- 오늘날 우리가 사용하는 컴퓨터는 동시에 단 한 개의 명령어만을 처리할 수 있다. 하지만, 이 부분의 처리 속도는
매우 빠르기 때문에 순간 적으로 여러 개의 명령어를 처리하는 것처럼 보이게 되는데, 우리가 개발한 프로그램 역시
매우 빠른 속도로 처리된다. 때문에 두 가지 이상의 작업이 거의 동시에 발생되고 처리 되어지게 할 수 있다.
이렇게 작업을 병렬로 처리하는 것은 그 만큼 작업 시간이 줄어드는 것이므로 효율은 높아지게 된다.
우리가 구성할 네트워크는 매우 많은 패킷들을 순간적으로 처리해주어야 한다. 때문에 병렬 처리가 필수적이라 할 수
있는데, 쓰레드라는 개념을 사용하여 이 것을 구현할 수 있다.
■ Thread란?
- 하나의 작업 프로세스를 진행시키는 단위라고 이해하면 된다. 우리가 프로그램 하나를 만들 때 그 프로그램은 main을
갖고 있으며, 프로그램dms main에서부터 시작한다. 이 때 O/S는 실행될 프로그램에 쓰레드를 하나 할당하고, 그 쓰레드
는 main함수를 실행하게 된다. 이렇게 실행된 프로그램에는 시스템으로부터 기본적으로 하나의 쓰레드가 주어지는데,
이 것을 메인 쓰레드(Main thread)라고 한다.
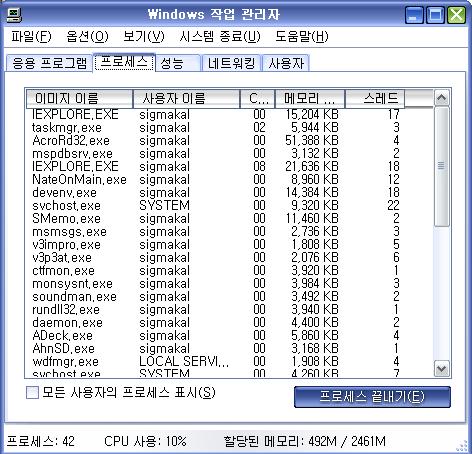
Ctrl + Alt + Del을 눌린후 보기에서 Thread보기를 선택하면 위와 같이 나온다.
위에서 각 프로세스마다 Thread의 수가 다름을 알 수 있다. 최소 1개이상이 사용된다.
■ Thread의 효율성
- 우리가 만드는 응용프로그램은 기본적으로 하나의 쓰레드를 할당 받아 작업을 진행한다. 때문에, 우리가 사용하는
Windows O/S는 이미 여러 개의 쓰레드가 동작하고 있는 것이다. 1 개의 CPU에서는 동시에 1개의 연산만이 가능하다고
하였다. 하지만 그 처리속도는 매우 빠르기 때문에, 여러 개의 쓰레드를 순차적으로 처리하게 되면 거의 동시에 처리되
어 지는 것으로 보여지게 되며, 이러한 방법으로 O/S는 우리에게 멀티 테스킹(Multitasking)을 지원할 수 있는 것이다.
하나의 쓰레드가 시작되었다고 해서 그 쓰레드가 끝날 때 까지 연속된 작업을 진행하는 것이 아니다. O/S는 쓰레드
하나가 한번에 진행할 수 있는 단위를 정하고 각 쓰레드들의 작업을 조금씩 진행시키는 병렬 처리를 한다.
이렇게 병렬로 작업되는 쓰레드를 우리는 응용 프로그램에서 임의로 생성하고 작업을 할당할 수 있다. 즉, 우리의
프로그램이 내부에서 작업을 병렬로 처리할 수 있다는 의미이다.
예를 들어, 한 서버에 두개의 클라이언트가 접속하였다고 하자. 클라이언트 들은 서로 작업 요청을 서버에 하게 되는데,
만일 서버가 메인 쓰레드만으로 모든 작업을 처리하려 한다면, 클라이언트로부터 들어오는 패킷을 쌓아놓고 순차적으
로 읽어 들여 처리하고 다시 통보해주어야 한다.
만일 여기에서 쓰레드를 더 생성하여 네트워크 작업과 내부 연산 작업을 병렬로 처리한다면 그만큼 처리 속도를 높일 수
있을 것이다.
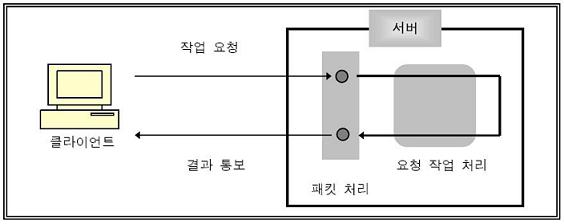
1. Server에 단일 Thread를 적용한 경우
Main Thread에서 모든 일들을 다 수행하고 있어서 순차적으로 읽어서 처리하고 다시 통보하므로, 속도가 느리고 비효율적이다.
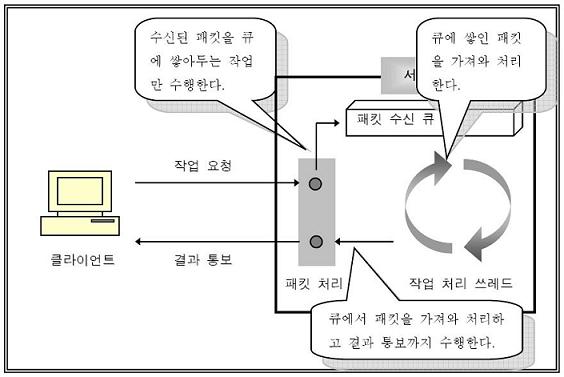
■ Context Switching
- 쓰레드는 O/S에서의 기본적인 스케줄링 단위이다. 그리고 이러한 쓰레드를 O/S는 여러 개를 관리하면서 우리에게
멀티 태스킹을 가능하게 해준다. 하지만 앞서 일반적인 CPU는 한번에 한가지 명령만을 계산할 수 있다고 하였다.
단지 여러 쓰레드의 순차적인 관리를 통해 거의 동시에 진행하게끔 한다고 하였는데, 이러한 관리를 위해서 쓰레드를
O/S에서 관리할 수 있는 기본적인 정보가 있어야 한다.
쓰레드는 레지스터(Register Set), 커널 스택(Kernel Stack), 사용자 스택 등의 여러 정보를 갖고 있는데, 이러한 정보들을
Context라고 한다. Context들은 쓰레드가 작업을 진행하는 동안 작업에 대한 정보를 보관하고 있으며, 다른 쓰레드로
작업 순서가 넘어갈 때 저장된다.
O/S는 쓰레드 하나의 작업을 진행하기 위해 그 쓰레드의 Context를 읽어오며, 다시 다른 쓰레드로 작업을 변경할 때
이전 쓰레드의 Context를 저장하고 다시 진행할 쓰레드의 Context를 읽어오는 작업을 반복하게된다.
이처럼 한 쓰레드에서 다른 쓰레드로 작업을 넘기는 과정을 Context Switching이라고 한다.
우리의 응용 프로그램 차원에서 보면, Context Switching이라는 작업은 아주 미묘하고 작은 단위이다. 그 속도 또한
무시해도 될 만큼 빠르기 때문에 우리는 그다지 신경을 쓰지 않아도 프로그램은 아주 잘 동작할 것이다.
하지만, 이렇게 처리해야 할 쓰레드의 개수가 매우 많다면 어떻게 될까? Windows O/S를 사용할 때 많은 프로그램들을
띄워놓고 작업하면 속도가 상당히 떨어짐을 느낄 수 있는데, 이 것은 작업해야 할 쓰레드가 많아짐에 따라 Context
Switching이 매우 빈번하게 발생하며, 다시 차례가 돌아오기까지의 시간이 더 소비되기 때문이다.
이처럼 Context Switching 작업은 매우 미묘할지라도 멀티 쓰레딩을 해야 하는 상황에서는 쓰레드의 개수에 신경을
써 주어야 한다. 병렬처리로 인해 작업 속도를 증가시킬 수는 있겠지만, 개수가 너무 많아지게 된다면 오히려 역효과를
가져올 수도 있으므로 신경써서 작업하고 성능 테스트를 꼭 해보길 바란다.
테스트라함은 작업관리자를 띄워서 성능을 봤을때 CPU의 사용률을 보면 알 수가 있다. Server를 만들어서 CPU사용률을
체크하는 습관을 가지자..
Ex)
while( 1 )
{
if( count == 0 ) // Sleep(1)을 걸어주지 않으면 CPU의 사용률은 100%이다.
Sleep( 1 );
Sleep( 1 );
}
- 위의 코드는 WorkerThread의 일부분을 단적인 예로 보여진 부분이다. 여기서 접속한 User가 아무도 없을 경우 미친듯이
while문을 돌게 된다.
그러면 CPU의 사용률이 100%을 보이지만, User가 아무도 없을시에 Sleep(1)을 걸어주면, CPU의 사용률이 10%이하로
내려감을 볼 수가 있다.
댓글 없음:
댓글 쓰기