2011년 2월 24일 목요일
Proactor pattern
http://blog.daum.net/aswip/8429554
[출처] http://www.cse.wustl.edu/~schmidt/PDF/proactor.pdf
1. 개요
현대의 운영체계들은 동시실행에 기초한 어플리케이션(서버)를 개발하는 것을 지원하기 위해 여러가지 매커니즘들을 제공한다.
동기적 멀티쓰레딩은 여러 동작이 동시다발적으로 실행되는 어플리케이션을 개발하는데 있어서 인기있는 매커니즘이다.
그렇지만 쓰레드는 종종 높은 성능 과부하를 가질 때가 있고, 동기화 패턴과 법칙들에 대한 깊은 지식을 요구한다.
그러므로, 여러 운영체계들은 동시실행 처리에 있어서 멀티쓰레딩의 과부하나 복잡도의 대부분을 완화시키는 장점이 있는
비동기적 매커니즘을 지원한다.
이 논문에서 제시하는 proactor 패턴은 운영체계에 의해 제공되는 비동기 매커니즘들을 효율적으로 다루는 어플리케이션과
시스템을 구축하는 법에 대해서 설명하고 있다. 어플리케이션이 비동기적인 작업을 수행할 때, 운영체계는 어플리케이션을 대신하여
작업을 실행한다. 이것은 어플리케이션으로 하여금 필요한 만큼의 수의 쓰레드를 가질 필요없이 동시에 동작하는 다수의 동작을
실행할 수 있게 해준다. 따라서, proactor 패턴은 서버 프로그래밍을 단순화 시켜주며, 비동기 처리를 위한 운영체계의 지원에
의존하고 보다 적은 쓰레드를 요구하게 됨으로써 성능을 증진시켜주게 된다.
2. 취지
Proactor 패턴은 비동기 이벤트들의 완료시점에 실행되는 다중 이벤트 핸들러들의 디스패칭과 디멀티플랙싱을 지원한다.
이 패턴은 완료 이벤트들의 디멀티플랙싱을 통합하고 그에 알맞은 이벤트 핸들러들을 디스패칭하는 것을 지원함으로써 비동기
기반의 어플리케이션 개발을 단순화해준다.
3. 동기
이 섹션은 proactor 패턴을 사용하기 위한 개념과 동기를 기술한다.
1) 고성능 서버의 의미과 능력
동기적인 방식의 멀티쓰레드 혹은 반응적인(reactive) 프로그래밍상에서 제약없이 동시처리방식으로 작업들을 실행시키려 하는데
성능상의 잇점이 요구될 때에는 proactor 패턴을 사용한다. 이 잇점들을 설명하기 위해서 동시처리방식으로 다중의 처리를 실행할
필요가 있는 네트워크 어플리케이션을 고려하자. 예를 들자면, 고성능의 웹서버는 반드시 여러개의 클라이언트 [1, 2]로부터 보내
어진 HTTP 요청들을 동시에 처리해야만 한다. "Figure 1"은 웹브라우져들과 웹서버사이의 전형적인 상호작용관계를 보여준다.
사용자가 브라우져에게 URL을 열도록 지시하면, 브라우져는 HTTP GET 요청을 웹 서버로 보낸다. 요청을 접수하면 서버는 요청을
파싱하고 적법한지 검사한 후, 지정된 화일(들)을 브라우져로 되돌려 보낸다.
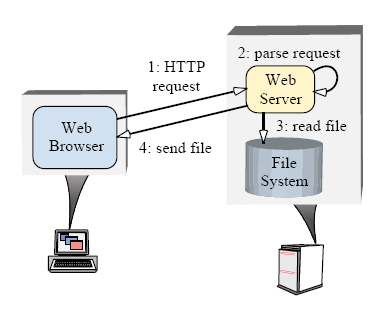 Figure 1. 일반적인 웹서버의 구조
Figure 1. 일반적인 웹서버의 구조
고성능의 웹서버가 개발되기 위해서는 다음 능력들을 가져야한다.
• 동시처리(Concurrency)
서버는 동시에 여러개의 클라이언트 요청을 수행해야만 한다.
• 효율성(Efficiency)
서버는 지연(latency)을 최소화해야하고, 대역폭을 최대로 활용해야 하며,
불필요하게 CPU(들)을 동작 시키는 것을 피해야한다.
• 프로그래밍 단순화(Programming simplicity)
서버의 디자인은 효율적인 동시처리에 대한 운영 전략의 적용을 단순화 할 수 있어야 한다.
• 적응성(Adaptability)
신규 혹은 개선된 트랜스포트 프로토콜(HTTP 1.1과 같은)을 지원하는데 있어서 최소한의 관리 비용이 들도록 해야한다.
웹서버는 몇가지 동시처리 전략(다중 동기화된 쓰레드방식, reactive한 동기적 이벤트 디스패칭, proactive한 비동기 이벤트 디스패칭)
들을 사용하여 구현될 수 있다. 아래에서 우리는 전통적인 접근 방식의 결점을 찾아보고 어떻게 proactor 패턴이 고성능의 서버
어플리케이션에 대한 효율적이고 유연한 비동기 이벤트 디스패칭 전략을 지원하는 강력한 태크닉을 제공하는지 살펴볼 것이다.
2) 전통적인 동시처리방식 서버모델들의 일반적인 덫과 함정들
동기화된 멀티쓰레딩과 reactive한 프로그래밍은 동시처리를 구현하는 일반적인 방법이다. 이 장은 이 프로그래밍 모델들에
대한 결점들을 설명한다.
3) 다중 동기화 쓰레드를 통한 동시처리
아마도 대부분의 동시처리방식의 웹서버를 구현하는 직관적인 방법은 동기적인 멀티쓰레딩 방식이다. 이 모델에서는 다중 서버
쓰레드들이 동시에 여러 클라이언트로 부터 HTTP GET 요청을 처리한다. 각 쓰레드는 접속 구축을 실행하고, HTTP 요청을 읽고,
요청을 파싱하며, 화일 전송 처리를 동기적으로 수행한다. 결과적으로 각 처리는 해당 처리가 완료될 때 까지 블럭당한다.
동기화된 쓰레딩 방식의 주된 잇점은 어플리케이션 코드의 단순함이다. 특별한 경우, 클라이언트 A의 요청을 서비스하기위해
웹서버에 의해 실행되는 처리들은 클라이언트 B의 요청을 서비스하기 위한 처리와는 대부분 독립적이다. 따라서, 쓰레드간에
공유되는 상태들의 양이 적기 때문에 별도의 쓰레드상에서 서로 다른 요청들을 서비스하는 것이 쉬운 것이다. (이것은 동기화의
필요성을 최소화하는 요인이다) 게다가, 별도의 쓰레드상에서 어플리케이션 로직을 실행하는 것은 개발자로 하여금 순차적인
명령들과 블록킹 처리를 다루는 것을 허용한다.
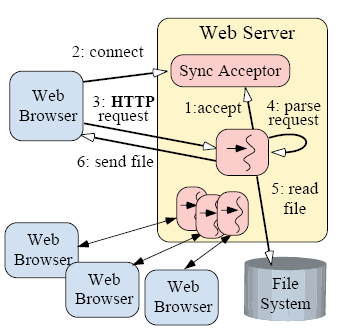 Figure 2. 멀티스레드 웹서버 구조
Figure 2. 멀티스레드 웹서버 구조
"Figure 2"는 어떻게 동기적인 쓰레드를 사용하여 디자인된 웹서버가 여러개의 클라이언트들을 동시실행방식으로 처리할 수
있는지 보여준다. 이 figure는 Sync Acceptor가 동기적으로 네트워크 접속을 accept 처리하기위한 서버측 구조를
은폐하고(encapsulate)있다는 것을 보여준다. "연결 1개당 쓰레드 1개" 방식을 사용해서 HTTP GET 요청을 서비스하기위한
각각의 쓰레드들의 실행단계는 다음과 같이 요약될 수 있다:
1. 각 쓰레드는 accept()함수실행시 클라이언트 접속요청이 올때까지 동기적으로 블록당한다.
2. 클라이언트가 서버에 연결되면, 접속이 accept된다. (블럭이 풀린다)
3. 새로 접속된 클라이언트의 HTTP 요청이 동기적으로 네트워크 연결을 통하여 읽혀진다.
4. 요청을 파싱한다.
5. 요청된 화일을 동기적으로 읽는다.
6. 화일의 내용이 동기적으로 클라이언트에게 전송된다.
동기적 쓰레드 모델을 적용한 웹서버를 C++ 코드 예제를 부록 A.1에 첨부해놓았다. 앞에서 기술했던 것처럼, 각각에 연결된
클라이언트는 전담(dedicated) 서버 쓰레드에 의해 동시처리적으로 서비스된다. 쓰레드는 다른 HTTP 요청을 서비스하기 전에
동기적으로 요청받은 처리를 완료한다. 그러므로, 여러 클라이언트에 대해 서비스하는동안 동기적 입출력을 실행하려면,
웹서버는 다중 쓰레드를 생성해야만 한다. 이 동기적 멀티쓰레드 모델이 직관적이고, 비교적 효과적으로 다중 CPU 체계에서
매핑된다고 할지라도, 이것은 다음과 같은 단점들을 가진다:
• 쓰레딩 정책이 동시처리 정책과 강하게 연관되어있다.
이 구조는 각 연결된 클라이언트들을 위한 개별적인 전담 쓰레드를 필요로 한다. 동시처리방식의 어플리케이션은 동시에
서비스되는 클라이언트의 수보다는 사용가능한 자원(쓰레드 풀링을 통한 CPU의 수와 같은 것)에 쓰레딩 전략을 맞추는 것에
의해 보다 더 최적화될 수 있다.
• 동기화의 복잡도 증가
쓰레드 처리는 서버의 공유 자원들(캐쉬된 화일이나 웹 페이지의 히트수 기록등등)에 대한 억세스를 직렬화하기위해서 필요한
동기화 체계에 대한 복잡도를 증가시킨다.
• 성능상의 과부하 증가
쓰레드 처리는 컨택스트 스위칭, 동기화, CPU간의 데이타 이동등에 기인하여 과부하상태로 실행될 수 있다.
• 비호환성
쓰레드는 모든 운영체계에 가능하지 않을 수도 있다. 게다가, 운영체계는 선점형 그리고 비선점형 쓰레드의 견지에서
보았을 경우 상당히 차이가 있다. 이런 이유로, 운영체계 플렛폼에 상관없이 동일하게 동작하는 다중 쓰레드방식의 서버를
만드는 것은 여려운 일이다.
이런 단점들 때문에, 멀티쓰레딩은 동시처리 방식의 웹서버를 개발하는데 있어서는 종종 아주 효율적이지도 않고 구조가 그리
간단하지도 않은 솔루션이 되고 있다.
4. 반응적(reactive) 이벤트 디스패칭을 통한 동시처리
또다른 동기적방식의 웹서버를 구현하는 일반적인 방법은 반응적(reactive) 이벤트 디스패칭 모델을 사용하는 것이다. reactor 패턴은
어떻게 어플리케이션이 Initiation Dispatcher를 사용하여 이벤트 핸들러를 등록할 수 있는지 보여준다. Initiation Dispatcher는 블록킹
없이 명령이 입회(initiate)가능할 경우 그에 알맞는 이벤트 핸들러를 알려준다. The Initiation Dispatcher notifies the Event Handler
when it is possible to initiate an operation without blocking. 싱글쓰레드 기반의 동시처리 방식 웹서버는 reactive 이벤트 디스패칭
모델을 사용할 수 있다. (이 모델은 reactor가 알맞은 명령이 들어왔음을 알려줄 때 까지 이벤트 루프상에서 기다리는 구조를 가진다.)
웹서버상의 reactive 명령에 대한 예는 Initiation Dispatcher을 사용한 acceptor의 등록작업이다. 데이타가 네트워크 연결을 통해서
도착하면, 디스패쳐는 acceptor를 콜백한다. acceptor는 네트워크 연결을 수락하고 HTTP 핸들러를 생성한다. 그런 다음 이 HTTP
핸들러는 웹서버의 싱글쓰레드 제어하에서 방금 진행되는 연결로 전송되어온 URL 요청을 처리하기 위해 reactor에 등록된다.
figure 3과 4는 반응적 이벤트 디스페칭을 사용하여 디자인된 웹서버가 여러개의 클라이언트를 어떻게 다루는지를 보여준다.
figure 3는 웹서버로 클라이언트가 접속할때 밟게되는 단계를 보여주며, figure 4는 웹서버가 어떻게 클라이언트 요청을 처리하는지
보여준다.
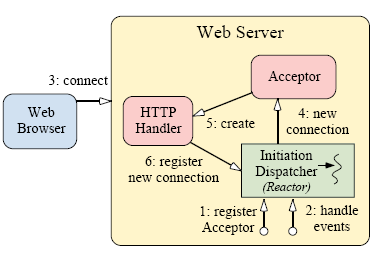 Figure 3. 클라이언트가 Reactive 웹서버에 접속
Figure 3. 클라이언트가 Reactive 웹서버에 접속
figure 3의 단계는 다음과 같이 요약될 수 있다:
1. 웹서버는 신규 접속을 accept처리하기 위한 Initiation Dispatcher에 acceptor를 등록한다.
(The Web Server registers an Acceptor with the Initiation Dispatcher to accept new connections.)
2. 웹서버는 Initiation Dispatcher의 이벤트루프를 동작시킨다.
3. 클라이언트가 웹서버에 접속한다.
4. acceptor가 신규 접속의 발생여부를 Initiation Dispatcher에게 알려주고 acceptor는 신규 접속을 받아들인다.
5. acceptor는 신규 클라이언트에 서비스하기위해 HTTP 핸들러를 생성한다.
6. HTTP 핸들러는 클라이언트의 요청 데이타를 읽기위해 Initiation Dispatcher에 접속정보를 등록한다.
(다시말하면, 접속상태를 "읽기대기"모드로 설정한다.)
7. HTTP 핸들러 서비스는 신규 클라이언트로부터의 요청에 따라 서비스를 시작한다.
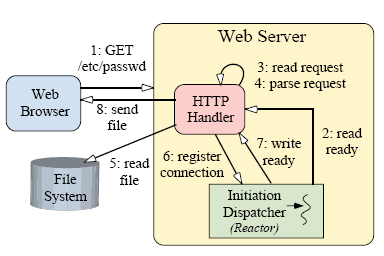 Figure 4. 클라이언트가 HTTP Request를 Reactive 웹서버에 요청
Figure 4. 클라이언트가 HTTP Request를 Reactive 웹서버에 요청
그림 4는 reactive 웹서버가 HTTP GET 요청을 서비스하는 단계를 보여준다. 그 과정은 다음과 같다:
1. 클라이언트는 HTTP GET 요청을 전송한다.
2. 클라이언트의 요청 데이타가 서버에 도착하였을때 Initiation Dispatcher는 HTTP 핸들러에게 그 사실을 알려준다.
3. 요청 데이타가 비블록상태로 읽혀진다.
(이것은 읽기명령이 즉시 수행을 끝내지 못했을 경우 EWOULDBLOCK을 반환하는 상태를 말한다.)
HTTP 요청데이타가 완전히 읽혀질때까지 2번과 3번단계를 반복한다.
4. HTTP 핸들러는 HTTP 요청을 파싱한다.
5. 요청된 화일을 동기적으로 화일 시스템으로 부터 읽는다.
6. HTTP 핸들러는 데이타를 보내기위해 Initiation Dispatcher에 연결정보를 등록한다.
(다시 말하면, 접속상태가 쓰기대기상태로 된다.)
7. Initiation Dispatcher는 TCP 접속이 쓰기모드 상태라는 것을 HTTP 핸들러에게 알려준다.
8. 요청 데이타가 클라이언트에게 비블록상태로 전송되어진다.
(이것은 쓰기명령이 즉시 수행을 끝내지 못했을 경우 EWOULDBLOCK을 반환하는 상태를 말한다.)
HTTP 요청데이타가 완전히 전송되어질때까지 7번과 8번단계를 반복한다.
reactive 이벤트 디스페칭 모델이 적용된 웹서버에 대한 C++ 코드 예제가 부록 A.2에 첨부되어있다. Initiation Dispatcher가
별도의 단일 쓰레드 상에서 실행되고 있기 까닭에 네트워크 입출력 명령들이 블록당하지 않는 상태로 reactor의 제어 아래에서
실행된다. If forward progress is stalled on the current operation, the operation is handed off to the Initiation Dispatcher,
which monitors the status of the system operation. 명령이 다시 우선 처리되는 상황이 오면, 알맞은 이벤트 핸들러에게
이 사실이 알려지게 된다.
reactive 모델의 주된 장점은 이식성, coarse-grained 동시처리 제어에 따른 낮은 과부하 (다시말하면, 싱글스레드 방식은 동기화나
컨텍스트 스위칭이 요구되지 않는다.), 디스페칭 체계로 부터 어플리케이션 로직을 분리함으로서 얻을수 있는 모듈화의 잇점들을
들 수 있다. 그럼에도 불구하고, 이 방식은 다음과 같은 단점들을 가지고 있다.
• 프로그램 복잡도의 증가
앞에서 언급했듯이, 서버가 특정 클라이언트에 대해 블록당하지 않고 서비스를 실행하려면 프로그래머는 복잡한 로직을
작성해야만 한다.
• 멀티쓰레딩에 대한 운영체계 지원의 부족
대부분의 운영체계들은 reactive 디스페칭 모델을 select() 함수로 구현한다[7]. 어쨌거나, select()는 같은 descriptor set에서 한개
이상의 쓰레드의 사용을 허용하지 않는다. 이것은 reactive 모델이 고성능의 서버의 제작에는 맞지 않다는 의미가 된다.
(하드웨어 병렬처리를 효율적으로 이용하려면 멀티쓰레드의 사용은 필수적이기 때문이다.)
• 실행가능한 task들의 스케줄링
선점형 쓰레드를 지원하는 동기방식의 멀티쓰레딩 구조하에서는, 설치된 CPU를 가지고 실행가능한 쓰레드들을 스케줄하고
시분할하여 제어하는 것은 운영체계의 역할이라고 할 수 있다. 이 스케줄링은 어플리케이션에서 한개의 쓰레드만이 존재하는
reactive 구조에서는 사용될 수 없다. 그러므로, 시스템 개발자는 웹서버에 연결된 모든 클라이언트들의 요청을 처리하는데
있어서 이 1개의 쓰레드의 실행단위를 주의깊게 시분할할 필요가 있다. 이것은 짧은 주기로 비블록 명령들을 실행함으로서 구현
될 수 있다.
요약하면, 이런 단점들 때문에 reactive 모델은 하드웨어 병렬처리가 지원된다면 그렇게 높은 효율을 기대할 수 있는 모델이 아니다.
이 모델은 또한 서버를 코딩하는 데 있어서 흔히 요구되는 입출력의 블록킹 회피를 구현하려면 다소 높은 수준의 프로그래밍 복잡도를
극복해야만 한다.
5. 해결책 : proactive 처리를 통한 동시처리
OS 플렛폼이 비동기 명령들을 지원할 경우, 고성능의 웹서버를 구현하는 효율적이고 편리한 방법은 proactive 이벤트 디스페칭을
사용하는 것이다. proactive 이벤트 디스페칭을 사용하여디자인된 웹 서버는 한개이상의 쓰레드를 제어하여 비동기명령의 완료여부를
다루는 것이 가능하다. 따라서, proactor 패턴은 완료 이벤트 디멀티플렉싱과 이벤트 핸들러 디스페칭을 통합함으로써 비동기방식의
웹서버 구조를 단순화시킨다.
비동기 웹서버는 운영체계에 처음에 비동기명령을 시동할 때와 명령이 완료했을 때를 알려주기 위한 완료 발송자
(completion dispatcher)에 콜백함수를 등록하기 위해 proactor 패턴을 사용할 수 있다. 운영체계는 이때 웹서버입장에서 명령을
수행하며 순차적으로 운영체계 내의 잘 알려진 곳에 결과를 적재(queue)한다. 완료 발송자(Completion Dispatcher)는 완료
알림메세지들을 뽑아내고(dequeue), 어플리케이션 동작위주의 웹서버 코드를 담은 알맞은 콜백함수를 실행하는 역할을 담당한다.
그림 5와 6은 proactor 패턴방식의 이벤트 디스패칭을 사용하여 디자인된 웹서버가 한개 이상의 쓰레드내에서 여러 클라이언트들을
어떻게 동시처리하는지를 보여준다.
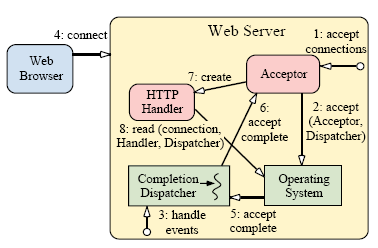 Figure 5. 클라이언트가 Proactive 방식의 웹서버에 접속
Figure 5. 클라이언트가 Proactive 방식의 웹서버에 접속
그림 5는 클라이언트가 웹서버로 접속했을때 실행되는 단계의 순서를 보여준다.
1. 웹서버는 acceptor에게 비동기 accept 처리를 초기화하도록 알려준다.
2. acceptor는 운영체계의 기능을 이용하여 비동기 accept 요청을 초기화하고, 그 자신을 완료 핸들러(Completion Handler)와
완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다. (이것은 비동기 accept의 완료여부를 acceptor에게 알려주는데
사용된다.)
3. 웹서버는 완료 발송자의 이벤트 루프를 실행한다.
4. 클라이언트가 웹서버에 접속한다.
5. 비동기 accept 명령이 완료하면, 운영체계는 완료 발송자에게 통지한다.
6. 완료 발송자는 acceptor에게 통지한다.
7. acceptor는 HTTP 핸들러를 생성한다.
8. HTTP 핸들러는 클라이언트로 부터 전송되는 요청 데이타를 비동기적으로 읽는 작업을 초기화하고 그 자신을
완료 핸들러(Completion Handler)와 완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다.
(이것은 비동기 읽기작업의 완료여부를 acceptor에게 알려주는데 사용된다.)
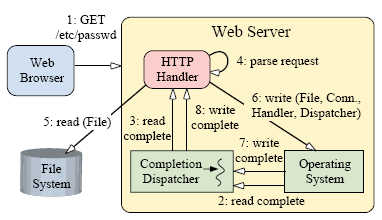 Figure 6. 클라이언트가 Proactive 방식의 웹서버에 요청을 보냄
Figure 6. 클라이언트가 Proactive 방식의 웹서버에 요청을 보냄
그림 6은 proactor 패턴을 적용한 웹서버가 HTTP GET 요청을 서비스하기위한 단계를 보여준다. 이 단계는 아래와 같다.
1. 클라이언트가 HTTP GET 요청을 전송한다.
2. 읽기 작업이 완료되면 운영체계는 완료 발송자에게 통지한다.
3. 완료 발송자는 HTTP 핸들러에게 통지한다. (2단계와 3단계는 전체 요청 메세지가 모두 전송받아질 때까지 반복하게 된다.)
4. HTTP 핸들러는 요청 데이타를 파싱한다.
5. HTTP 핸들러가 동기적으로 요청된 화일을 읽어들인다.
6. HTTP 핸들러는 화일 데이타를 접속된 클라이언트로 전송하기위한 비동기 명령을 초기화한다. 그리고 그 자신을 완료 핸들러
(Completion Handler)와 완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다. 이것은 비동기 화일전송작업의
완료여부를 HTTP 핸들러에게 통지하는데 사용된다.
7. 전송작업이 완료되면 운영체계는 완료 발송자에게 통지한다.
8. 이때 완료 발송자는 완료 핸들러에게 통지한다. (6~8단계는 화일이 모두 전송될때까지 반복된다.)
웹서버에 proactor 이벤트 디스페칭 모델을 적용한 C++ 코드예제가 8장에 소개되어있다. proactor 패턴을 적용했을 때 가장
큰 잇점은 다중으로 실행되는 동시처리 명령들을 꼭 여러개의 쓰레드를 필요로 하지않으면서 병렬적으로 시동하고 실행할 수
있다는 점이다. 각 명령들은 비동기적으로 어플리케이션에 의해 시동되며, 운영체계의 입출력 부속시스템내에서 완료될 때 까지
실행을 계속한다. 이제 명령들을 초기화하는 쓰레드는 한가지 작업만을 전담하지 않고 추가된 요청들을 서비스해주는 것이
가능하다. 예를 들자면, 앞의 예제에서 완료 발송자는 단일 쓰레드 방식이 될 수 있는 것이다. HTTP 요청이 서버에 도착하면,
단일 완료발송자 쓰레드는 요청 메세지를 파싱하고, 화일을 읽고, 클라이언트에게 요청에 대한 응답을 전송한다. 응답이
비동기적으로 보내어지기 때문에, 다수의 응답을 동시에 부분적으로 처리할 수 있게 되는 것이다. 게다가, 동기적 화일읽기 작업은
비동기 화일읽기 작업으로 교체할 수도 있을 것이다. (이러면 동시처리될 가능성이 더 높아지게된다.) 만약 화일읽기작업이
비동기적으로 수행된다면, HTTP 핸들러에 의해 처리되는 단 하나의 동기적 작업은 HTTP 프로토콜 파싱밖에 없게 된다.
proactor 모델의 주요 단점은 reactor 모델보다 프로그래밍 로직이 보다 더 복잡해질 수 있다는 것 이다. 게다가, 비동기 명령들은
가끔 예측하기 힘들고 반복되지않는 실행순서를 가지는 까닭에 proactor 패턴은 실행 분석과 디버그하기가 다소 어렵다. 7장은
비동기 어플리케이션을 단순화시켜주는 (비동기 완료 토큰[8]과 같은) 다른 패턴들을 적용시키는 방법에 대해 설명하고 있다.
6. 적용해야 할 경우
proactor 패턴은 다음과 같은 조건을 한개 이상 만족할 때 사용하기를 권장한다.
• 호출되는 쓰레드를 블록하지 않고 한개 이상의 비동기 명령들을 실행할 필요가 있을 때.
• 비동기 명령들이 완료될 때를 통지받아야 할 때.
• 입출력 모델에 독립적으로 다양한 동시처리 전략이 요구될 때.
• 어플리케이션 독립적으로 구현된 하부구조로부터 어플리케이션 의존적인 로직을 흡수할 경우 잇점이 많을 때.
• 멀티쓰레딩 방식 혹은 reactor 디스패칭 방식으로는 성능이 기대한 것보다 낮거나 비효율적인 경우.
7. 구조와 구성요소들
proactor 패턴의 구조는 figure 7에 OMT 표기법으로 그려져있다.
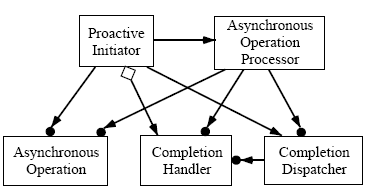 Figure 7. Proactor 패턴의 구성요소들
Figure 7. Proactor 패턴의 구성요소들
proactor 패턴의 핵심 구성요소는 다음과 같다:
• Proactive Initiator (웹서버 어플리케이션의 주 쓰레드)
어플리케이션 요소중의 하나이며 비동기 명령을 초기화 한다.
Proactive Initiator는 완료 핸들러를 완료 발송자에게 등록한다. 완료 디스패쳐는 명령이 완료되었을때 통보해준다.
• 완료(Completion) 핸들러 (the Acceptor and HTTP Handler)
Proactor패턴에서는 완료 핸들러를 비동기 명령이 완료되었을때 어플리케이션으로 통보해주기위한 인터페이스로 사용한다.
• 비동기 명령 (the methods Async Read, Async Write, and Async Accept)
비동기 명령은 어플리케이션의 입장에서 요청을 실행하기 위한 용도로 사용된다. 어플리케이션이 비동기 명령을 호출하면
해당 명령은 어플리케이션의 스레드 컨트롤을 가져오지 않고 수행된다.(이에 반해 reactive 이벤트 분배 모델은 명령은 동기적으로
수행하기위해 어플리케이션의 스레드 컨트롤을 빼앗아온다) 따라서, 어플리케이션의 관점에서 보면 명령은 비동기적으로 수행된다.
비동기 명령이 완료되면 비동기 명령 프로세서는 어플리케이션에게 통보하는 일을 완료 분배자에게 위임한다.
• 비동기 명령 프로세서 (the Operating System)
비동기 명령 프로세서는 비동기 명령을 실행한다(명령이 완료될때까지). 이 컴포넌트는 일반적으로 OS에 의해 구현된다.
• 완료(Completion) 분배자 (the Notification Queue)
완료 분배자는 비동기 명령이 완료되었을때 어플리케이션의 완료 핸들러를 호출해준다. 비동기 명령 프로세서가 비동기적으로
초기화 명령을 완료했을때도 완료 분배자는 어플리케이션의 입장에서 콜백을 수행해준다.
8. Collaborations
모든 비동기 명령에 대해 몇개의 잘 디자인된 단계가 있다. 높은 수준의 추상화 레벨에서 어플리케이션은 비동기적으로 명령을
초기화하고 명령이 완료되었을때 통보받는다. Figure 8은 패턴 구성요소들 사이에 반드시 일어나야하는 다음 상호작용들을 보여준다.
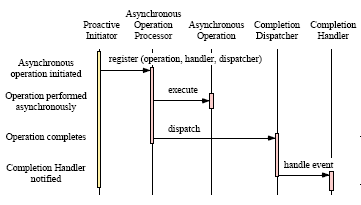 Figure 8. Proactor패턴을 위한 상호작용 다이어그램
Figure 8. Proactor패턴을 위한 상호작용 다이어그램
1. Proactive 초기자는 명령을 초기화
비동기 명령을 수행하기 위해서 어플리케이션은 비동기 명령 프로세서에서 명령을 초기화 해야한다. 예를 들면 웹서버는 OS에게
특정한 소켓을 이용하여 파일을 네트워크 너머로 전송하겠다고 요청할수도 있다. 그런 명령을 요청하기 위해서는 웹서버는 반드시
사용하고자하는 파일과 네트워크 커넥션을 명시해야한다. 더욱이, 웹서버는 파일 전송이 완료되었을때 어떤 완료 핸들러로 통보를
받을지, 어떤 완료 분배자가 콜백을 수행해줄지도 명시해야한다.
2. 완료 명령 프로세서는 명령을 수행
어플리케이션이 명령을 호출하면 비동기 명령 프로세서는 비동기적으로 명령을 수행해준다.
현대 OS(솔라리스나 윈도우 NT 같은)는 커널단에서 비동기 IO 서브시스템을 제공해준다.
3. 비동기 명령 프로세서는 완료 분배자에게 완료를 통보
명령이 완료되었을 때, 비동기 명령 프로세서는 명령이 초기화될때 명시되었던 완료 핸들러와 완료 분배자를 찾아낸다.
그리고 비동기 명령의 결과와 콜백을 위한 완료 핸들러를 완료 분배자에게 넘겨준다. 예를 들어 비동기 파일 전송이 완료되었을때
명령의 결과(성공인지 실패인지)와 몇바이트가 전송되었는지를 알려준다.
4. 완료 분배자는 어플리케이션에게 완료를 통보
완료 분배자는 결과 데이터를 어플리케이션에게 알려주기 위해 완료 핸들러를 호출한다. 예를 들어 비동기 읽기 명령이 완료되면
완료 핸들러는 일반적으로 새로 도착한 데이터(방금 읽어낸 데이터)의 포인터를 넘겨준다.
9. 결론
이 장은 Proactor 패턴의 장단점을 설명한다.
1) 장점
proactor 패턴은 다음과 같은 장점들을 가지고 있다:
• 고려사항에 대한 구분이 보다 더 명확함
Proactor 패턴은 어플리케이션과는 독립적인 비동기 체계들을 어플리케이션 고유의 기능과 분리시켜준다. 어플리케이션에
독립적인 메커니즘들(비동기 명령과 관련된 완료 이벤트들을 어떻게 디멀티플렉싱하는가, 완료 핸들러에 정의된 콜백 함수를
어떻게 분배하는가)은 재사용이 가능한 컴포넌트가 된다. 마찬가지로 어플리케이션에 명시된 기능들은 특정한 서비스들을
수행한다 (HTTP처리와 같은).
• 어플리케이션 로직의 이식성 증가
이벤트 디멜티플렉싱을 수행하는 OS의 호출로부터 독립적인 인터페이스는 어플리케이션의 이식성을 향상시켜준다. 이런 시스템
호출들은 여러 이벤트로부터 동시에 발생할수도 있다. 이벤트 소스는 IO포트, 타이머, 동기화 객체, 시그널 등을 포함할 수도 있다.
실시간 POSIX 플랫폼에서 비동기 함수들은 aio family of API들로 부터 제공된다. 윈도우즈 NT에서는 IO completion port나
overlapped IO로 비동기 IO를 구현한다.
• 완료 분배자가 동시처리 체계를 은폐(encapsulate)시켜준다.
완료 분배자를 비동기 명령 프로세서로부터 분리시키는 장점중의 하나는 어플리케이션이 다른 구성요소들에게 영향을 미치지
않으면서도 완료 분배자를 다양한 동시처리 전략으로 설정할수 있다는 점이다. 섹션 7에서 논의된 바와 같이 완료 분배자는 싱글
스레드 혹은 스레드 풀과 같이 다양한 동시처리 전략으로 설정이 가능하다.
• 쓰레딩 정책이 동시처리 정책과 분리된다.
비동기 명령 프로세서가 오래 걸릴수도 있는 명령들을 Proactive Initiator를 대신하여 처리해주기 때문에 어플리케이션은 굳이
스레드를 여러개 생성하지 않아도 된다. 이것은 어플리케이션이 스레딩 정책을 독립적으로 설정할수 있게 해준다. 예를 들어
웹서버는 하나의 CPU에 하나의 스레드만을 사용할수도 있다. 하지만 많은 수의 브라우저들의 끊임없는 요청을 처리해주기
위해서는 더 많은 스레드가 필요할 수도 있다.
• 효율의 증가
멀티스레드 OS는 여러 스레드사이에 컨텍스트 스위칭을 반복수행한다. 이런 작업중에 OS가 놀고있는 스레드에 컨텍스트
스위칭을 한다면 전체 어플리케이션의 성능은 두드러지게 떨어질수 있다. 예를 들어 비효율적인 스레드에 완료를 poll 한다거나. Proactor 패턴은이벤트 진행의 컨트롤이 가능한 스레드만 활성화 시키기 때문에 이런 컨텍스트 스위칭 비용이 들지 않는다.
예를 들면 웹서버는 현재 pending 되어있는 GET 요청이 없다면 HTTP 핸들러를 활성화 시키지 않는다.
• 어플리케이션 동기화의 단순화
완료 핸들러 자체에서 스레드를 생성하지 않는 한, 어플리케이션 로직은 동기화 이슈에 대한 고려없이 작성되어도 된다.
완료 핸들러는 마치 전통적인 싱글 스레드 환경에 있는 것 처럼 작성될수도 있다. 예를 들면 웹서버의 HTTP Get 핸들러는
비동기 읽기 명령(윈도우즈의 TransmitFile 함수와 같은)을 통해 디스크를 액세스 할 수 있다.
2) 단점
proactor 패턴은 다음과 같은 단점들을 가지고 있다:
• 디버그하기 어렵다
proactor 패턴을 사용하여 개발된 어플리케이션은 디버그하기가 어려워질 수 있다. (이것은 뒤집어진 제어 흐름이 프레임워크
하부구조와 어플리케이션에서 정의된 핸들러상의 콜백사이를 왔다갔다하기 때문이다. 한마디로 추적하다보면 내가 어디있지?
하는 부분을 말한다.) 이 때문에 프레임워크의 실행과정 중에 "한줄한줄씩 밟아나가는 방식"의 디버그는 정말로 어려워질 수 있다.
(어플리케이션 개발자들은 프레임워크의 소스 코드를 가지고 있지 않거나 이해하지 못하기 때문이다) 이것은 LEX나 YACC으로
쓰여진 컴파일러의 구문 분석기나 파서를 디버그할 때 부딛히는 문제와 비슷하다. 이런 형태의 어플리케이션에서는, 제어되는
쓰레드가 사용자 정의된 액션 루틴상에 있을때 디버깅은 수월해질 수 있다. (In these applications, debugging is
straightforward when the thread of control is within the user-defined action routines.) 한번 제어 쓰레드가
유한결정오토마타(DFA : Deterministic Finite Automata)를 생성하고 반환되면, 어찌되었던간에 프로그램 로직을
따라가는 것은 힘들어진다.
• 두드러진(outstanding) 명령처리와 스케줄링
Proactive Initiators는 비동기 명령들이 실행되는 순서를 조정할 수 없을 수도 있다. 그러므로, 비동기 명령 프로세서는 비동기
명령들의 우선순위지정과 취소기능을 지원하도록 주의깊게 제작되어야 한다.
10. 구현
Proactor 패턴은 다양한 방법으로 구현될 수 있다. 이 장은 Proactor 패턴을 구현하는데 필요한 단계를 알아본다.
1) 비동기 명령 프로세서의 구현
Proactor 패턴을 구현하는 첫번째 단계는 비동기 명령 프로세서는 만드는 일이다. 비동기 명령 프로세서는 어플리케이션을
대신하여 명령을 비동기적으로 수행해주는 역할을 한다. 이것의 결과로 비동기 명령 API들을 정의하는 일과 비동기 명령 엔진을
만드는 두 가지 해야 할 일이 생긴다.
2) 비동기 명령 API를 정의하기
비동기 명령 프로세서는 반드시 비동기 명령을 요청할 수 있는 API들을 제공해야 한다. 아래에 API들을 디자인하는데 고려해야
할 사항이 있다.
• 이식성
API는 어플리케이션이나 Proactor Initiator에 종속되어서는 안된다.
• 융통성
종종 비동기 API는 많은 타입의 명령에 공유된다. 예를 들면 비동기 IO 명령은 다중 IO작업을 수행하기 위한 방편으로 사용
될수도 있다(네트워크나 파일 같은). 이런 재사용을 지원하도록 API를 디자인하는 것이 유익할 수 있다.
• 콜백
Proactor Initiator는 반드시 명령이 호출될때 콜백을 등록해야한다. 콜백을 구현하기위한 일반적인 방법은 calling object나
caller라고 불리는 인터페이스를 export하는 방법이 있다. Proactor Initiator는 반드시 비동기 명령 프로세서에게 명령이
완료되면 호출될 완료 핸들러를 알려야한다.
• 완료 디스패쳐
어플리케이션이 다중 완료 분배자를 사용할 수도 있기 때문에Proactor Initiator 또한 어떤 완료 분배자가 콜백을 수행해
줄 것인지 명시해야 한다.
이런 사항들을 감안한, 비동기 읽기와 쓰기를 제공하는 API가 있다. Asynch_Stream클래스는 비동기 읽기와 쓰기를 초기화 하는
팩토리이다. 한번 생성되면 여러개의 읽기와 쓰기 작업이 이 클래스를 이용하여 시작될 수 있다. 비동기 읽기 작업이 완료되면
Asynch_Stream::Read_Result 클래스가 완료 핸들러에 있는 handle_read 함수를 통해 전달될 것이다. 마찬가지로 비동기 쓰기
작업이 완료되면Asynch_Stream::Write_Result 클래스가 완료 핸들러에 있는 handle_write 함수를 통해 전달될 것이다.
3) 비동기 명령 엔진 구현하기
비동기 명령 프로세서는 반드시 명령을 비동기 방식으로 수행하는 메커니즘을 포함해야한다. 다르게 설명하면, 어플리케이션
스레드가 비동기 명령을 수행하면 이 명령은 어플리케이션의 스레드 컨트롤을 가져오지 않고 수행되어야 한다(블로킹되지 않고
바로 리턴되어야 한다는 의미). 다행히도 현대의 OS들은 비동기 명령을 위한 메커니즘을 제공한다(예를 들면 POSIX 비동기 I/O나
Windows NT의 overlapped I/O). 이 경우에는 이 패턴을 구현하는 부분은 단순히 플랫폼의 API들과 위에 서술된 비동기 명령들과
매핑만 시켜주면 된다. 하지만 만일 OS가 비동기 명령을 지원하지 않는다면 비동기 명령엔진을 구현하는 몇가지 테크닉이 있다.
가장 직관적인 해결법은 전용 스레드에서 어플리케이션의 요청한 비동기 명령을 수행하는 방법일 것이다. 스레드된 비동기 명령을
구현하기 위해서는 몇가지 단계가 있다.
11. 알려진 사용처
아래는 Proactor 패턴을 사용했다고 알려진 곳들이다.
• I/O Completion Ports in Windows NT
Windows NT는 Proactor 패턴을 구현하고 있다. 새로운 네트워크 커넥션을 받는 명령, 파일이나 소켓을 읽거나 쓰는 명령,
네트워크 커넥션을 통해 파일을 전송하는 명령이 Windows NT에 의해 제공된다. OS가 바로 비동기 명령 프로세서 이다.
명령의 결과는 I/O completion port에 쌓인다(이것이 완료 분배자의 역할을 수행).
• The Unix AIO Family of Asynchronous I/O Operations
실시간 POSIX 플랫폼에서는 Proactor패턴이 aio family of APIS로 구현되어있다. 이런 OS의 기능들은 위에 기술된 Windows NT와
상당히 유사하다. 한가지 다른 점이 있다면 UNIX 시그널은 진짜 비동기 완료 분배자로 구현되어있다.
(Windows NT의 API는 진짜 비동기 방식은 아니다)
• ACE Proactor
ACE의 비동기 컴포넌트들은 Windows NT의 I/O Completion Ports와 UNIX 플랫폼의 aio APIs를 캡슐화한다.
ACE Proactor의 추상화는 Windows NT의 표준 C APIs를 통해 객체지향 인터페이스를 제공한다. 소스코드는 ACE 웹사이트에서
얻을수 있다(www.cs.wustl.edu/_schmidt/ACE.html).
• Asynchronous Procedure Calls in Windows NT
어떤 시스템(Windows NT와 같은)은 비동기 프로시져 콜(APC)을 지원한다. APC는 함수는 비동기적으로 특정한 스레드에서
실행되게 해준다. APC가 스레드에 queue되면 시스템은 소프트웨어 인터럽트를 실행한다. 다음번에 스레드가 schedule되면
APC에서 실행된다. OS에 의해 만들어지는 것을 커널모드 APC라고 하고 어플리케이션에 의해 만들어지는 것을 유저모드
APC라고 한다.
12. 관련이 있는 패턴들
Figure 9는 Proactor와 관련이 있는 패턴들을 보여주고 있다.
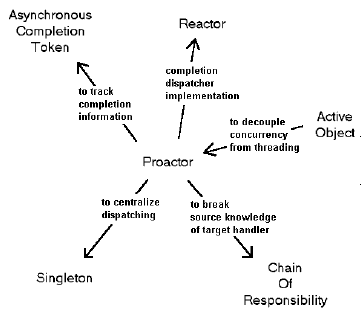 Figure 9. Proactor패턴과 연관된 패턴들
Figure 9. Proactor패턴과 연관된 패턴들
The Asynchronous Completion Token (ACT) 패턴은 일반적으로 Proactor 패턴과 결함되어 쓰인다. 비동기 명령이
완료되었을때, 어플리케이션은 이벤트를 적절하게 다루기 위해 단순히 통보만 받는 것보다 더 많은 정보가 필요할 수도 있다.
The Asynchronous Completion Token 패턴은 어플리케이션이 비동기 동작 완료와 관련있는 정보를 효율적으로 알수
있게 해준다.
[출처] http://www.cse.wustl.edu/~schmidt/PDF/proactor.pdf
1. 개요
현대의 운영체계들은 동시실행에 기초한 어플리케이션(서버)를 개발하는 것을 지원하기 위해 여러가지 매커니즘들을 제공한다.
동기적 멀티쓰레딩은 여러 동작이 동시다발적으로 실행되는 어플리케이션을 개발하는데 있어서 인기있는 매커니즘이다.
그렇지만 쓰레드는 종종 높은 성능 과부하를 가질 때가 있고, 동기화 패턴과 법칙들에 대한 깊은 지식을 요구한다.
그러므로, 여러 운영체계들은 동시실행 처리에 있어서 멀티쓰레딩의 과부하나 복잡도의 대부분을 완화시키는 장점이 있는
비동기적 매커니즘을 지원한다.
이 논문에서 제시하는 proactor 패턴은 운영체계에 의해 제공되는 비동기 매커니즘들을 효율적으로 다루는 어플리케이션과
시스템을 구축하는 법에 대해서 설명하고 있다. 어플리케이션이 비동기적인 작업을 수행할 때, 운영체계는 어플리케이션을 대신하여
작업을 실행한다. 이것은 어플리케이션으로 하여금 필요한 만큼의 수의 쓰레드를 가질 필요없이 동시에 동작하는 다수의 동작을
실행할 수 있게 해준다. 따라서, proactor 패턴은 서버 프로그래밍을 단순화 시켜주며, 비동기 처리를 위한 운영체계의 지원에
의존하고 보다 적은 쓰레드를 요구하게 됨으로써 성능을 증진시켜주게 된다.
2. 취지
Proactor 패턴은 비동기 이벤트들의 완료시점에 실행되는 다중 이벤트 핸들러들의 디스패칭과 디멀티플랙싱을 지원한다.
이 패턴은 완료 이벤트들의 디멀티플랙싱을 통합하고 그에 알맞은 이벤트 핸들러들을 디스패칭하는 것을 지원함으로써 비동기
기반의 어플리케이션 개발을 단순화해준다.
3. 동기
이 섹션은 proactor 패턴을 사용하기 위한 개념과 동기를 기술한다.
1) 고성능 서버의 의미과 능력
동기적인 방식의 멀티쓰레드 혹은 반응적인(reactive) 프로그래밍상에서 제약없이 동시처리방식으로 작업들을 실행시키려 하는데
성능상의 잇점이 요구될 때에는 proactor 패턴을 사용한다. 이 잇점들을 설명하기 위해서 동시처리방식으로 다중의 처리를 실행할
필요가 있는 네트워크 어플리케이션을 고려하자. 예를 들자면, 고성능의 웹서버는 반드시 여러개의 클라이언트 [1, 2]로부터 보내
어진 HTTP 요청들을 동시에 처리해야만 한다. "Figure 1"은 웹브라우져들과 웹서버사이의 전형적인 상호작용관계를 보여준다.
사용자가 브라우져에게 URL을 열도록 지시하면, 브라우져는 HTTP GET 요청을 웹 서버로 보낸다. 요청을 접수하면 서버는 요청을
파싱하고 적법한지 검사한 후, 지정된 화일(들)을 브라우져로 되돌려 보낸다.
고성능의 웹서버가 개발되기 위해서는 다음 능력들을 가져야한다.
• 동시처리(Concurrency)
서버는 동시에 여러개의 클라이언트 요청을 수행해야만 한다.
• 효율성(Efficiency)
서버는 지연(latency)을 최소화해야하고, 대역폭을 최대로 활용해야 하며,
불필요하게 CPU(들)을 동작 시키는 것을 피해야한다.
• 프로그래밍 단순화(Programming simplicity)
서버의 디자인은 효율적인 동시처리에 대한 운영 전략의 적용을 단순화 할 수 있어야 한다.
• 적응성(Adaptability)
신규 혹은 개선된 트랜스포트 프로토콜(HTTP 1.1과 같은)을 지원하는데 있어서 최소한의 관리 비용이 들도록 해야한다.
웹서버는 몇가지 동시처리 전략(다중 동기화된 쓰레드방식, reactive한 동기적 이벤트 디스패칭, proactive한 비동기 이벤트 디스패칭)
들을 사용하여 구현될 수 있다. 아래에서 우리는 전통적인 접근 방식의 결점을 찾아보고 어떻게 proactor 패턴이 고성능의 서버
어플리케이션에 대한 효율적이고 유연한 비동기 이벤트 디스패칭 전략을 지원하는 강력한 태크닉을 제공하는지 살펴볼 것이다.
2) 전통적인 동시처리방식 서버모델들의 일반적인 덫과 함정들
동기화된 멀티쓰레딩과 reactive한 프로그래밍은 동시처리를 구현하는 일반적인 방법이다. 이 장은 이 프로그래밍 모델들에
대한 결점들을 설명한다.
3) 다중 동기화 쓰레드를 통한 동시처리
아마도 대부분의 동시처리방식의 웹서버를 구현하는 직관적인 방법은 동기적인 멀티쓰레딩 방식이다. 이 모델에서는 다중 서버
쓰레드들이 동시에 여러 클라이언트로 부터 HTTP GET 요청을 처리한다. 각 쓰레드는 접속 구축을 실행하고, HTTP 요청을 읽고,
요청을 파싱하며, 화일 전송 처리를 동기적으로 수행한다. 결과적으로 각 처리는 해당 처리가 완료될 때 까지 블럭당한다.
동기화된 쓰레딩 방식의 주된 잇점은 어플리케이션 코드의 단순함이다. 특별한 경우, 클라이언트 A의 요청을 서비스하기위해
웹서버에 의해 실행되는 처리들은 클라이언트 B의 요청을 서비스하기 위한 처리와는 대부분 독립적이다. 따라서, 쓰레드간에
공유되는 상태들의 양이 적기 때문에 별도의 쓰레드상에서 서로 다른 요청들을 서비스하는 것이 쉬운 것이다. (이것은 동기화의
필요성을 최소화하는 요인이다) 게다가, 별도의 쓰레드상에서 어플리케이션 로직을 실행하는 것은 개발자로 하여금 순차적인
명령들과 블록킹 처리를 다루는 것을 허용한다.
"Figure 2"는 어떻게 동기적인 쓰레드를 사용하여 디자인된 웹서버가 여러개의 클라이언트들을 동시실행방식으로 처리할 수
있는지 보여준다. 이 figure는 Sync Acceptor가 동기적으로 네트워크 접속을 accept 처리하기위한 서버측 구조를
은폐하고(encapsulate)있다는 것을 보여준다. "연결 1개당 쓰레드 1개" 방식을 사용해서 HTTP GET 요청을 서비스하기위한
각각의 쓰레드들의 실행단계는 다음과 같이 요약될 수 있다:
1. 각 쓰레드는 accept()함수실행시 클라이언트 접속요청이 올때까지 동기적으로 블록당한다.
2. 클라이언트가 서버에 연결되면, 접속이 accept된다. (블럭이 풀린다)
3. 새로 접속된 클라이언트의 HTTP 요청이 동기적으로 네트워크 연결을 통하여 읽혀진다.
4. 요청을 파싱한다.
5. 요청된 화일을 동기적으로 읽는다.
6. 화일의 내용이 동기적으로 클라이언트에게 전송된다.
동기적 쓰레드 모델을 적용한 웹서버를 C++ 코드 예제를 부록 A.1에 첨부해놓았다. 앞에서 기술했던 것처럼, 각각에 연결된
클라이언트는 전담(dedicated) 서버 쓰레드에 의해 동시처리적으로 서비스된다. 쓰레드는 다른 HTTP 요청을 서비스하기 전에
동기적으로 요청받은 처리를 완료한다. 그러므로, 여러 클라이언트에 대해 서비스하는동안 동기적 입출력을 실행하려면,
웹서버는 다중 쓰레드를 생성해야만 한다. 이 동기적 멀티쓰레드 모델이 직관적이고, 비교적 효과적으로 다중 CPU 체계에서
매핑된다고 할지라도, 이것은 다음과 같은 단점들을 가진다:
• 쓰레딩 정책이 동시처리 정책과 강하게 연관되어있다.
이 구조는 각 연결된 클라이언트들을 위한 개별적인 전담 쓰레드를 필요로 한다. 동시처리방식의 어플리케이션은 동시에
서비스되는 클라이언트의 수보다는 사용가능한 자원(쓰레드 풀링을 통한 CPU의 수와 같은 것)에 쓰레딩 전략을 맞추는 것에
의해 보다 더 최적화될 수 있다.
• 동기화의 복잡도 증가
쓰레드 처리는 서버의 공유 자원들(캐쉬된 화일이나 웹 페이지의 히트수 기록등등)에 대한 억세스를 직렬화하기위해서 필요한
동기화 체계에 대한 복잡도를 증가시킨다.
• 성능상의 과부하 증가
쓰레드 처리는 컨택스트 스위칭, 동기화, CPU간의 데이타 이동등에 기인하여 과부하상태로 실행될 수 있다.
• 비호환성
쓰레드는 모든 운영체계에 가능하지 않을 수도 있다. 게다가, 운영체계는 선점형 그리고 비선점형 쓰레드의 견지에서
보았을 경우 상당히 차이가 있다. 이런 이유로, 운영체계 플렛폼에 상관없이 동일하게 동작하는 다중 쓰레드방식의 서버를
만드는 것은 여려운 일이다.
이런 단점들 때문에, 멀티쓰레딩은 동시처리 방식의 웹서버를 개발하는데 있어서는 종종 아주 효율적이지도 않고 구조가 그리
간단하지도 않은 솔루션이 되고 있다.
4. 반응적(reactive) 이벤트 디스패칭을 통한 동시처리
또다른 동기적방식의 웹서버를 구현하는 일반적인 방법은 반응적(reactive) 이벤트 디스패칭 모델을 사용하는 것이다. reactor 패턴은
어떻게 어플리케이션이 Initiation Dispatcher를 사용하여 이벤트 핸들러를 등록할 수 있는지 보여준다. Initiation Dispatcher는 블록킹
없이 명령이 입회(initiate)가능할 경우 그에 알맞는 이벤트 핸들러를 알려준다. The Initiation Dispatcher notifies the Event Handler
when it is possible to initiate an operation without blocking. 싱글쓰레드 기반의 동시처리 방식 웹서버는 reactive 이벤트 디스패칭
모델을 사용할 수 있다. (이 모델은 reactor가 알맞은 명령이 들어왔음을 알려줄 때 까지 이벤트 루프상에서 기다리는 구조를 가진다.)
웹서버상의 reactive 명령에 대한 예는 Initiation Dispatcher을 사용한 acceptor의 등록작업이다. 데이타가 네트워크 연결을 통해서
도착하면, 디스패쳐는 acceptor를 콜백한다. acceptor는 네트워크 연결을 수락하고 HTTP 핸들러를 생성한다. 그런 다음 이 HTTP
핸들러는 웹서버의 싱글쓰레드 제어하에서 방금 진행되는 연결로 전송되어온 URL 요청을 처리하기 위해 reactor에 등록된다.
figure 3과 4는 반응적 이벤트 디스페칭을 사용하여 디자인된 웹서버가 여러개의 클라이언트를 어떻게 다루는지를 보여준다.
figure 3는 웹서버로 클라이언트가 접속할때 밟게되는 단계를 보여주며, figure 4는 웹서버가 어떻게 클라이언트 요청을 처리하는지
보여준다.
figure 3의 단계는 다음과 같이 요약될 수 있다:
1. 웹서버는 신규 접속을 accept처리하기 위한 Initiation Dispatcher에 acceptor를 등록한다.
(The Web Server registers an Acceptor with the Initiation Dispatcher to accept new connections.)
2. 웹서버는 Initiation Dispatcher의 이벤트루프를 동작시킨다.
3. 클라이언트가 웹서버에 접속한다.
4. acceptor가 신규 접속의 발생여부를 Initiation Dispatcher에게 알려주고 acceptor는 신규 접속을 받아들인다.
5. acceptor는 신규 클라이언트에 서비스하기위해 HTTP 핸들러를 생성한다.
6. HTTP 핸들러는 클라이언트의 요청 데이타를 읽기위해 Initiation Dispatcher에 접속정보를 등록한다.
(다시말하면, 접속상태를 "읽기대기"모드로 설정한다.)
7. HTTP 핸들러 서비스는 신규 클라이언트로부터의 요청에 따라 서비스를 시작한다.
그림 4는 reactive 웹서버가 HTTP GET 요청을 서비스하는 단계를 보여준다. 그 과정은 다음과 같다:
1. 클라이언트는 HTTP GET 요청을 전송한다.
2. 클라이언트의 요청 데이타가 서버에 도착하였을때 Initiation Dispatcher는 HTTP 핸들러에게 그 사실을 알려준다.
3. 요청 데이타가 비블록상태로 읽혀진다.
(이것은 읽기명령이 즉시 수행을 끝내지 못했을 경우 EWOULDBLOCK을 반환하는 상태를 말한다.)
HTTP 요청데이타가 완전히 읽혀질때까지 2번과 3번단계를 반복한다.
4. HTTP 핸들러는 HTTP 요청을 파싱한다.
5. 요청된 화일을 동기적으로 화일 시스템으로 부터 읽는다.
6. HTTP 핸들러는 데이타를 보내기위해 Initiation Dispatcher에 연결정보를 등록한다.
(다시 말하면, 접속상태가 쓰기대기상태로 된다.)
7. Initiation Dispatcher는 TCP 접속이 쓰기모드 상태라는 것을 HTTP 핸들러에게 알려준다.
8. 요청 데이타가 클라이언트에게 비블록상태로 전송되어진다.
(이것은 쓰기명령이 즉시 수행을 끝내지 못했을 경우 EWOULDBLOCK을 반환하는 상태를 말한다.)
HTTP 요청데이타가 완전히 전송되어질때까지 7번과 8번단계를 반복한다.
reactive 이벤트 디스페칭 모델이 적용된 웹서버에 대한 C++ 코드 예제가 부록 A.2에 첨부되어있다. Initiation Dispatcher가
별도의 단일 쓰레드 상에서 실행되고 있기 까닭에 네트워크 입출력 명령들이 블록당하지 않는 상태로 reactor의 제어 아래에서
실행된다. If forward progress is stalled on the current operation, the operation is handed off to the Initiation Dispatcher,
which monitors the status of the system operation. 명령이 다시 우선 처리되는 상황이 오면, 알맞은 이벤트 핸들러에게
이 사실이 알려지게 된다.
reactive 모델의 주된 장점은 이식성, coarse-grained 동시처리 제어에 따른 낮은 과부하 (다시말하면, 싱글스레드 방식은 동기화나
컨텍스트 스위칭이 요구되지 않는다.), 디스페칭 체계로 부터 어플리케이션 로직을 분리함으로서 얻을수 있는 모듈화의 잇점들을
들 수 있다. 그럼에도 불구하고, 이 방식은 다음과 같은 단점들을 가지고 있다.
• 프로그램 복잡도의 증가
앞에서 언급했듯이, 서버가 특정 클라이언트에 대해 블록당하지 않고 서비스를 실행하려면 프로그래머는 복잡한 로직을
작성해야만 한다.
• 멀티쓰레딩에 대한 운영체계 지원의 부족
대부분의 운영체계들은 reactive 디스페칭 모델을 select() 함수로 구현한다[7]. 어쨌거나, select()는 같은 descriptor set에서 한개
이상의 쓰레드의 사용을 허용하지 않는다. 이것은 reactive 모델이 고성능의 서버의 제작에는 맞지 않다는 의미가 된다.
(하드웨어 병렬처리를 효율적으로 이용하려면 멀티쓰레드의 사용은 필수적이기 때문이다.)
• 실행가능한 task들의 스케줄링
선점형 쓰레드를 지원하는 동기방식의 멀티쓰레딩 구조하에서는, 설치된 CPU를 가지고 실행가능한 쓰레드들을 스케줄하고
시분할하여 제어하는 것은 운영체계의 역할이라고 할 수 있다. 이 스케줄링은 어플리케이션에서 한개의 쓰레드만이 존재하는
reactive 구조에서는 사용될 수 없다. 그러므로, 시스템 개발자는 웹서버에 연결된 모든 클라이언트들의 요청을 처리하는데
있어서 이 1개의 쓰레드의 실행단위를 주의깊게 시분할할 필요가 있다. 이것은 짧은 주기로 비블록 명령들을 실행함으로서 구현
될 수 있다.
요약하면, 이런 단점들 때문에 reactive 모델은 하드웨어 병렬처리가 지원된다면 그렇게 높은 효율을 기대할 수 있는 모델이 아니다.
이 모델은 또한 서버를 코딩하는 데 있어서 흔히 요구되는 입출력의 블록킹 회피를 구현하려면 다소 높은 수준의 프로그래밍 복잡도를
극복해야만 한다.
5. 해결책 : proactive 처리를 통한 동시처리
OS 플렛폼이 비동기 명령들을 지원할 경우, 고성능의 웹서버를 구현하는 효율적이고 편리한 방법은 proactive 이벤트 디스페칭을
사용하는 것이다. proactive 이벤트 디스페칭을 사용하여디자인된 웹 서버는 한개이상의 쓰레드를 제어하여 비동기명령의 완료여부를
다루는 것이 가능하다. 따라서, proactor 패턴은 완료 이벤트 디멀티플렉싱과 이벤트 핸들러 디스페칭을 통합함으로써 비동기방식의
웹서버 구조를 단순화시킨다.
비동기 웹서버는 운영체계에 처음에 비동기명령을 시동할 때와 명령이 완료했을 때를 알려주기 위한 완료 발송자
(completion dispatcher)에 콜백함수를 등록하기 위해 proactor 패턴을 사용할 수 있다. 운영체계는 이때 웹서버입장에서 명령을
수행하며 순차적으로 운영체계 내의 잘 알려진 곳에 결과를 적재(queue)한다. 완료 발송자(Completion Dispatcher)는 완료
알림메세지들을 뽑아내고(dequeue), 어플리케이션 동작위주의 웹서버 코드를 담은 알맞은 콜백함수를 실행하는 역할을 담당한다.
그림 5와 6은 proactor 패턴방식의 이벤트 디스패칭을 사용하여 디자인된 웹서버가 한개 이상의 쓰레드내에서 여러 클라이언트들을
어떻게 동시처리하는지를 보여준다.
그림 5는 클라이언트가 웹서버로 접속했을때 실행되는 단계의 순서를 보여준다.
1. 웹서버는 acceptor에게 비동기 accept 처리를 초기화하도록 알려준다.
2. acceptor는 운영체계의 기능을 이용하여 비동기 accept 요청을 초기화하고, 그 자신을 완료 핸들러(Completion Handler)와
완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다. (이것은 비동기 accept의 완료여부를 acceptor에게 알려주는데
사용된다.)
3. 웹서버는 완료 발송자의 이벤트 루프를 실행한다.
4. 클라이언트가 웹서버에 접속한다.
5. 비동기 accept 명령이 완료하면, 운영체계는 완료 발송자에게 통지한다.
6. 완료 발송자는 acceptor에게 통지한다.
7. acceptor는 HTTP 핸들러를 생성한다.
8. HTTP 핸들러는 클라이언트로 부터 전송되는 요청 데이타를 비동기적으로 읽는 작업을 초기화하고 그 자신을
완료 핸들러(Completion Handler)와 완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다.
(이것은 비동기 읽기작업의 완료여부를 acceptor에게 알려주는데 사용된다.)
그림 6은 proactor 패턴을 적용한 웹서버가 HTTP GET 요청을 서비스하기위한 단계를 보여준다. 이 단계는 아래와 같다.
1. 클라이언트가 HTTP GET 요청을 전송한다.
2. 읽기 작업이 완료되면 운영체계는 완료 발송자에게 통지한다.
3. 완료 발송자는 HTTP 핸들러에게 통지한다. (2단계와 3단계는 전체 요청 메세지가 모두 전송받아질 때까지 반복하게 된다.)
4. HTTP 핸들러는 요청 데이타를 파싱한다.
5. HTTP 핸들러가 동기적으로 요청된 화일을 읽어들인다.
6. HTTP 핸들러는 화일 데이타를 접속된 클라이언트로 전송하기위한 비동기 명령을 초기화한다. 그리고 그 자신을 완료 핸들러
(Completion Handler)와 완료 발송자(Completion Dispatcher)의 참조로써 넘기게 된다. 이것은 비동기 화일전송작업의
완료여부를 HTTP 핸들러에게 통지하는데 사용된다.
7. 전송작업이 완료되면 운영체계는 완료 발송자에게 통지한다.
8. 이때 완료 발송자는 완료 핸들러에게 통지한다. (6~8단계는 화일이 모두 전송될때까지 반복된다.)
웹서버에 proactor 이벤트 디스페칭 모델을 적용한 C++ 코드예제가 8장에 소개되어있다. proactor 패턴을 적용했을 때 가장
큰 잇점은 다중으로 실행되는 동시처리 명령들을 꼭 여러개의 쓰레드를 필요로 하지않으면서 병렬적으로 시동하고 실행할 수
있다는 점이다. 각 명령들은 비동기적으로 어플리케이션에 의해 시동되며, 운영체계의 입출력 부속시스템내에서 완료될 때 까지
실행을 계속한다. 이제 명령들을 초기화하는 쓰레드는 한가지 작업만을 전담하지 않고 추가된 요청들을 서비스해주는 것이
가능하다. 예를 들자면, 앞의 예제에서 완료 발송자는 단일 쓰레드 방식이 될 수 있는 것이다. HTTP 요청이 서버에 도착하면,
단일 완료발송자 쓰레드는 요청 메세지를 파싱하고, 화일을 읽고, 클라이언트에게 요청에 대한 응답을 전송한다. 응답이
비동기적으로 보내어지기 때문에, 다수의 응답을 동시에 부분적으로 처리할 수 있게 되는 것이다. 게다가, 동기적 화일읽기 작업은
비동기 화일읽기 작업으로 교체할 수도 있을 것이다. (이러면 동시처리될 가능성이 더 높아지게된다.) 만약 화일읽기작업이
비동기적으로 수행된다면, HTTP 핸들러에 의해 처리되는 단 하나의 동기적 작업은 HTTP 프로토콜 파싱밖에 없게 된다.
proactor 모델의 주요 단점은 reactor 모델보다 프로그래밍 로직이 보다 더 복잡해질 수 있다는 것 이다. 게다가, 비동기 명령들은
가끔 예측하기 힘들고 반복되지않는 실행순서를 가지는 까닭에 proactor 패턴은 실행 분석과 디버그하기가 다소 어렵다. 7장은
비동기 어플리케이션을 단순화시켜주는 (비동기 완료 토큰[8]과 같은) 다른 패턴들을 적용시키는 방법에 대해 설명하고 있다.
6. 적용해야 할 경우
proactor 패턴은 다음과 같은 조건을 한개 이상 만족할 때 사용하기를 권장한다.
• 호출되는 쓰레드를 블록하지 않고 한개 이상의 비동기 명령들을 실행할 필요가 있을 때.
• 비동기 명령들이 완료될 때를 통지받아야 할 때.
• 입출력 모델에 독립적으로 다양한 동시처리 전략이 요구될 때.
• 어플리케이션 독립적으로 구현된 하부구조로부터 어플리케이션 의존적인 로직을 흡수할 경우 잇점이 많을 때.
• 멀티쓰레딩 방식 혹은 reactor 디스패칭 방식으로는 성능이 기대한 것보다 낮거나 비효율적인 경우.
7. 구조와 구성요소들
proactor 패턴의 구조는 figure 7에 OMT 표기법으로 그려져있다.
proactor 패턴의 핵심 구성요소는 다음과 같다:
• Proactive Initiator (웹서버 어플리케이션의 주 쓰레드)
어플리케이션 요소중의 하나이며 비동기 명령을 초기화 한다.
Proactive Initiator는 완료 핸들러를 완료 발송자에게 등록한다. 완료 디스패쳐는 명령이 완료되었을때 통보해준다.
• 완료(Completion) 핸들러 (the Acceptor and HTTP Handler)
Proactor패턴에서는 완료 핸들러를 비동기 명령이 완료되었을때 어플리케이션으로 통보해주기위한 인터페이스로 사용한다.
• 비동기 명령 (the methods Async Read, Async Write, and Async Accept)
비동기 명령은 어플리케이션의 입장에서 요청을 실행하기 위한 용도로 사용된다. 어플리케이션이 비동기 명령을 호출하면
해당 명령은 어플리케이션의 스레드 컨트롤을 가져오지 않고 수행된다.(이에 반해 reactive 이벤트 분배 모델은 명령은 동기적으로
수행하기위해 어플리케이션의 스레드 컨트롤을 빼앗아온다) 따라서, 어플리케이션의 관점에서 보면 명령은 비동기적으로 수행된다.
비동기 명령이 완료되면 비동기 명령 프로세서는 어플리케이션에게 통보하는 일을 완료 분배자에게 위임한다.
• 비동기 명령 프로세서 (the Operating System)
비동기 명령 프로세서는 비동기 명령을 실행한다(명령이 완료될때까지). 이 컴포넌트는 일반적으로 OS에 의해 구현된다.
• 완료(Completion) 분배자 (the Notification Queue)
완료 분배자는 비동기 명령이 완료되었을때 어플리케이션의 완료 핸들러를 호출해준다. 비동기 명령 프로세서가 비동기적으로
초기화 명령을 완료했을때도 완료 분배자는 어플리케이션의 입장에서 콜백을 수행해준다.
8. Collaborations
모든 비동기 명령에 대해 몇개의 잘 디자인된 단계가 있다. 높은 수준의 추상화 레벨에서 어플리케이션은 비동기적으로 명령을
초기화하고 명령이 완료되었을때 통보받는다. Figure 8은 패턴 구성요소들 사이에 반드시 일어나야하는 다음 상호작용들을 보여준다.
1. Proactive 초기자는 명령을 초기화
비동기 명령을 수행하기 위해서 어플리케이션은 비동기 명령 프로세서에서 명령을 초기화 해야한다. 예를 들면 웹서버는 OS에게
특정한 소켓을 이용하여 파일을 네트워크 너머로 전송하겠다고 요청할수도 있다. 그런 명령을 요청하기 위해서는 웹서버는 반드시
사용하고자하는 파일과 네트워크 커넥션을 명시해야한다. 더욱이, 웹서버는 파일 전송이 완료되었을때 어떤 완료 핸들러로 통보를
받을지, 어떤 완료 분배자가 콜백을 수행해줄지도 명시해야한다.
2. 완료 명령 프로세서는 명령을 수행
어플리케이션이 명령을 호출하면 비동기 명령 프로세서는 비동기적으로 명령을 수행해준다.
현대 OS(솔라리스나 윈도우 NT 같은)는 커널단에서 비동기 IO 서브시스템을 제공해준다.
3. 비동기 명령 프로세서는 완료 분배자에게 완료를 통보
명령이 완료되었을 때, 비동기 명령 프로세서는 명령이 초기화될때 명시되었던 완료 핸들러와 완료 분배자를 찾아낸다.
그리고 비동기 명령의 결과와 콜백을 위한 완료 핸들러를 완료 분배자에게 넘겨준다. 예를 들어 비동기 파일 전송이 완료되었을때
명령의 결과(성공인지 실패인지)와 몇바이트가 전송되었는지를 알려준다.
4. 완료 분배자는 어플리케이션에게 완료를 통보
완료 분배자는 결과 데이터를 어플리케이션에게 알려주기 위해 완료 핸들러를 호출한다. 예를 들어 비동기 읽기 명령이 완료되면
완료 핸들러는 일반적으로 새로 도착한 데이터(방금 읽어낸 데이터)의 포인터를 넘겨준다.
9. 결론
이 장은 Proactor 패턴의 장단점을 설명한다.
1) 장점
proactor 패턴은 다음과 같은 장점들을 가지고 있다:
• 고려사항에 대한 구분이 보다 더 명확함
Proactor 패턴은 어플리케이션과는 독립적인 비동기 체계들을 어플리케이션 고유의 기능과 분리시켜준다. 어플리케이션에
독립적인 메커니즘들(비동기 명령과 관련된 완료 이벤트들을 어떻게 디멀티플렉싱하는가, 완료 핸들러에 정의된 콜백 함수를
어떻게 분배하는가)은 재사용이 가능한 컴포넌트가 된다. 마찬가지로 어플리케이션에 명시된 기능들은 특정한 서비스들을
수행한다 (HTTP처리와 같은).
• 어플리케이션 로직의 이식성 증가
이벤트 디멜티플렉싱을 수행하는 OS의 호출로부터 독립적인 인터페이스는 어플리케이션의 이식성을 향상시켜준다. 이런 시스템
호출들은 여러 이벤트로부터 동시에 발생할수도 있다. 이벤트 소스는 IO포트, 타이머, 동기화 객체, 시그널 등을 포함할 수도 있다.
실시간 POSIX 플랫폼에서 비동기 함수들은 aio family of API들로 부터 제공된다. 윈도우즈 NT에서는 IO completion port나
overlapped IO로 비동기 IO를 구현한다.
• 완료 분배자가 동시처리 체계를 은폐(encapsulate)시켜준다.
완료 분배자를 비동기 명령 프로세서로부터 분리시키는 장점중의 하나는 어플리케이션이 다른 구성요소들에게 영향을 미치지
않으면서도 완료 분배자를 다양한 동시처리 전략으로 설정할수 있다는 점이다. 섹션 7에서 논의된 바와 같이 완료 분배자는 싱글
스레드 혹은 스레드 풀과 같이 다양한 동시처리 전략으로 설정이 가능하다.
• 쓰레딩 정책이 동시처리 정책과 분리된다.
비동기 명령 프로세서가 오래 걸릴수도 있는 명령들을 Proactive Initiator를 대신하여 처리해주기 때문에 어플리케이션은 굳이
스레드를 여러개 생성하지 않아도 된다. 이것은 어플리케이션이 스레딩 정책을 독립적으로 설정할수 있게 해준다. 예를 들어
웹서버는 하나의 CPU에 하나의 스레드만을 사용할수도 있다. 하지만 많은 수의 브라우저들의 끊임없는 요청을 처리해주기
위해서는 더 많은 스레드가 필요할 수도 있다.
• 효율의 증가
멀티스레드 OS는 여러 스레드사이에 컨텍스트 스위칭을 반복수행한다. 이런 작업중에 OS가 놀고있는 스레드에 컨텍스트
스위칭을 한다면 전체 어플리케이션의 성능은 두드러지게 떨어질수 있다. 예를 들어 비효율적인 스레드에 완료를 poll 한다거나. Proactor 패턴은이벤트 진행의 컨트롤이 가능한 스레드만 활성화 시키기 때문에 이런 컨텍스트 스위칭 비용이 들지 않는다.
예를 들면 웹서버는 현재 pending 되어있는 GET 요청이 없다면 HTTP 핸들러를 활성화 시키지 않는다.
• 어플리케이션 동기화의 단순화
완료 핸들러 자체에서 스레드를 생성하지 않는 한, 어플리케이션 로직은 동기화 이슈에 대한 고려없이 작성되어도 된다.
완료 핸들러는 마치 전통적인 싱글 스레드 환경에 있는 것 처럼 작성될수도 있다. 예를 들면 웹서버의 HTTP Get 핸들러는
비동기 읽기 명령(윈도우즈의 TransmitFile 함수와 같은)을 통해 디스크를 액세스 할 수 있다.
2) 단점
proactor 패턴은 다음과 같은 단점들을 가지고 있다:
• 디버그하기 어렵다
proactor 패턴을 사용하여 개발된 어플리케이션은 디버그하기가 어려워질 수 있다. (이것은 뒤집어진 제어 흐름이 프레임워크
하부구조와 어플리케이션에서 정의된 핸들러상의 콜백사이를 왔다갔다하기 때문이다. 한마디로 추적하다보면 내가 어디있지?
하는 부분을 말한다.) 이 때문에 프레임워크의 실행과정 중에 "한줄한줄씩 밟아나가는 방식"의 디버그는 정말로 어려워질 수 있다.
(어플리케이션 개발자들은 프레임워크의 소스 코드를 가지고 있지 않거나 이해하지 못하기 때문이다) 이것은 LEX나 YACC으로
쓰여진 컴파일러의 구문 분석기나 파서를 디버그할 때 부딛히는 문제와 비슷하다. 이런 형태의 어플리케이션에서는, 제어되는
쓰레드가 사용자 정의된 액션 루틴상에 있을때 디버깅은 수월해질 수 있다. (In these applications, debugging is
straightforward when the thread of control is within the user-defined action routines.) 한번 제어 쓰레드가
유한결정오토마타(DFA : Deterministic Finite Automata)를 생성하고 반환되면, 어찌되었던간에 프로그램 로직을
따라가는 것은 힘들어진다.
• 두드러진(outstanding) 명령처리와 스케줄링
Proactive Initiators는 비동기 명령들이 실행되는 순서를 조정할 수 없을 수도 있다. 그러므로, 비동기 명령 프로세서는 비동기
명령들의 우선순위지정과 취소기능을 지원하도록 주의깊게 제작되어야 한다.
10. 구현
Proactor 패턴은 다양한 방법으로 구현될 수 있다. 이 장은 Proactor 패턴을 구현하는데 필요한 단계를 알아본다.
1) 비동기 명령 프로세서의 구현
Proactor 패턴을 구현하는 첫번째 단계는 비동기 명령 프로세서는 만드는 일이다. 비동기 명령 프로세서는 어플리케이션을
대신하여 명령을 비동기적으로 수행해주는 역할을 한다. 이것의 결과로 비동기 명령 API들을 정의하는 일과 비동기 명령 엔진을
만드는 두 가지 해야 할 일이 생긴다.
2) 비동기 명령 API를 정의하기
비동기 명령 프로세서는 반드시 비동기 명령을 요청할 수 있는 API들을 제공해야 한다. 아래에 API들을 디자인하는데 고려해야
할 사항이 있다.
• 이식성
API는 어플리케이션이나 Proactor Initiator에 종속되어서는 안된다.
• 융통성
종종 비동기 API는 많은 타입의 명령에 공유된다. 예를 들면 비동기 IO 명령은 다중 IO작업을 수행하기 위한 방편으로 사용
될수도 있다(네트워크나 파일 같은). 이런 재사용을 지원하도록 API를 디자인하는 것이 유익할 수 있다.
• 콜백
Proactor Initiator는 반드시 명령이 호출될때 콜백을 등록해야한다. 콜백을 구현하기위한 일반적인 방법은 calling object나
caller라고 불리는 인터페이스를 export하는 방법이 있다. Proactor Initiator는 반드시 비동기 명령 프로세서에게 명령이
완료되면 호출될 완료 핸들러를 알려야한다.
• 완료 디스패쳐
어플리케이션이 다중 완료 분배자를 사용할 수도 있기 때문에Proactor Initiator 또한 어떤 완료 분배자가 콜백을 수행해
줄 것인지 명시해야 한다.
이런 사항들을 감안한, 비동기 읽기와 쓰기를 제공하는 API가 있다. Asynch_Stream클래스는 비동기 읽기와 쓰기를 초기화 하는
팩토리이다. 한번 생성되면 여러개의 읽기와 쓰기 작업이 이 클래스를 이용하여 시작될 수 있다. 비동기 읽기 작업이 완료되면
Asynch_Stream::Read_Result 클래스가 완료 핸들러에 있는 handle_read 함수를 통해 전달될 것이다. 마찬가지로 비동기 쓰기
작업이 완료되면Asynch_Stream::Write_Result 클래스가 완료 핸들러에 있는 handle_write 함수를 통해 전달될 것이다.
3) 비동기 명령 엔진 구현하기
비동기 명령 프로세서는 반드시 명령을 비동기 방식으로 수행하는 메커니즘을 포함해야한다. 다르게 설명하면, 어플리케이션
스레드가 비동기 명령을 수행하면 이 명령은 어플리케이션의 스레드 컨트롤을 가져오지 않고 수행되어야 한다(블로킹되지 않고
바로 리턴되어야 한다는 의미). 다행히도 현대의 OS들은 비동기 명령을 위한 메커니즘을 제공한다(예를 들면 POSIX 비동기 I/O나
Windows NT의 overlapped I/O). 이 경우에는 이 패턴을 구현하는 부분은 단순히 플랫폼의 API들과 위에 서술된 비동기 명령들과
매핑만 시켜주면 된다. 하지만 만일 OS가 비동기 명령을 지원하지 않는다면 비동기 명령엔진을 구현하는 몇가지 테크닉이 있다.
가장 직관적인 해결법은 전용 스레드에서 어플리케이션의 요청한 비동기 명령을 수행하는 방법일 것이다. 스레드된 비동기 명령을
구현하기 위해서는 몇가지 단계가 있다.
11. 알려진 사용처
아래는 Proactor 패턴을 사용했다고 알려진 곳들이다.
• I/O Completion Ports in Windows NT
Windows NT는 Proactor 패턴을 구현하고 있다. 새로운 네트워크 커넥션을 받는 명령, 파일이나 소켓을 읽거나 쓰는 명령,
네트워크 커넥션을 통해 파일을 전송하는 명령이 Windows NT에 의해 제공된다. OS가 바로 비동기 명령 프로세서 이다.
명령의 결과는 I/O completion port에 쌓인다(이것이 완료 분배자의 역할을 수행).
• The Unix AIO Family of Asynchronous I/O Operations
실시간 POSIX 플랫폼에서는 Proactor패턴이 aio family of APIS로 구현되어있다. 이런 OS의 기능들은 위에 기술된 Windows NT와
상당히 유사하다. 한가지 다른 점이 있다면 UNIX 시그널은 진짜 비동기 완료 분배자로 구현되어있다.
(Windows NT의 API는 진짜 비동기 방식은 아니다)
• ACE Proactor
ACE의 비동기 컴포넌트들은 Windows NT의 I/O Completion Ports와 UNIX 플랫폼의 aio APIs를 캡슐화한다.
ACE Proactor의 추상화는 Windows NT의 표준 C APIs를 통해 객체지향 인터페이스를 제공한다. 소스코드는 ACE 웹사이트에서
얻을수 있다(www.cs.wustl.edu/_schmidt/ACE.html).
• Asynchronous Procedure Calls in Windows NT
어떤 시스템(Windows NT와 같은)은 비동기 프로시져 콜(APC)을 지원한다. APC는 함수는 비동기적으로 특정한 스레드에서
실행되게 해준다. APC가 스레드에 queue되면 시스템은 소프트웨어 인터럽트를 실행한다. 다음번에 스레드가 schedule되면
APC에서 실행된다. OS에 의해 만들어지는 것을 커널모드 APC라고 하고 어플리케이션에 의해 만들어지는 것을 유저모드
APC라고 한다.
12. 관련이 있는 패턴들
Figure 9는 Proactor와 관련이 있는 패턴들을 보여주고 있다.
The Asynchronous Completion Token (ACT) 패턴은 일반적으로 Proactor 패턴과 결함되어 쓰인다. 비동기 명령이
완료되었을때, 어플리케이션은 이벤트를 적절하게 다루기 위해 단순히 통보만 받는 것보다 더 많은 정보가 필요할 수도 있다.
The Asynchronous Completion Token 패턴은 어플리케이션이 비동기 동작 완료와 관련있는 정보를 효율적으로 알수
있게 해준다.
2011년 2월 23일 수요일
ThreadPool 과 Work Stealing
ThreadPool은 병렬 혹은 동시 프로그래밍에서 빠질 수 없는 도구다.
여러 코어 혹은 CPU를 활용하는 측면에서나 과도하게 Thread가 생성되는 비효율성을 줄이는 측면에서나 ThreadPool은 좋은 해답이 된다.
그러나 일반적인 ThreadPool의 구현에서도 병목이 되는 부분이 생기는데, 바로 ThreadPool에 맡겨질 WorkItem 들을 담고 있는 Queue 부분이다.
ThreadPool에 있는 여러 Thread가 하나의 Queue에서 WorkItem을 가져가려고 하는 Race Conditon이 발생하기 때문에 동기화가 필요하다. 특히 코어 혹은 CPU가 늘어나면 Thread도 그 만큼 많아지므로 경합(Contention)이 더욱 심해진다.
결국 하나의 Queue를 사용하는 ThreadPool은 확장성(scalability)이 떨어진다.
이런 경합이 발생하는 문제를 해결하는 방법은 의외로 간단할 수 있다. Queue를 하나만 사용해서 생기는 문제이기 때문에, Queue를 여러개 사용하면 된다. 즉 Thread마다 하나씩 Queue를 가질 수 있게 두는 것이다.
Thread 마다 자신의 전용 Queue를 만들어 두고, 해당 Thread에서 ThreadPool에 WorkItem을 추가하는 부분이 나오면 자신의 Queue에다가 추가해 두고, 또한 WorkItem을 처리할 때도 자신의 Queue에서 WorkItem을 가져다가 처리하게 되면 ThreadPool의 다른 Thread와 하나의 Queue를 두고 경합하는 상황을 피할 수 있다.
위 부분을 읽으면서 어렴풋이 느끼겠지만, 이건 뭔가 부족한 해결방법이다.
예를 들어 하나의 WorkItem을 처리하면 새로운 WorkItem이 여러개 생기는 형태의 작업인 경우에는, ThreadPool에 있는 Thread 중에 하나의 Thread에만 집중적으로 WorkItem이 몰리게 되는 현상이 발생하게 된다. 즉 한 Thread에는 작업이 넘쳐나는데, 다른 Thread는 놀고 있게 된다. Thread의 효율적인 활용에 문제가 생기게 되는 것이다.
이렇게 Thread 전용의 Queue를 사용함으로써 생기는 Thread간 불균형을 해결하기 위한 방법이 Work Stealing이다.
개념은 쉽다. 한 Thread가 자신의 Queue에 더이상 처리할 WorkItem이 없다면 다른 Thread의 Queue에 있는 WorkItem을 가져다가(Steal) 자신이 실행하는 것이다.
앞서 설명한 ThreadPool에 이 Work Stealing 기능을 추가하면, 혹 다른 Thread에 WorkItem이 집중되는 상황이 생기더라도, 여유가 있는 Thread가 그 WorkItem을 가져다가 실행시키게 될 것이므로 WorkItem은 비교적 공평하게 ThreadPool의 Thread들에게 분배가 된다.
따라서 확장성을 높이면서도 Thread가 비균등 현상을 해결할 수 있는 ThreadPool을 만들 수 있게 된다.
하지만...
얼핏 느낀분들도 있을거라 생각하는데, Work Stealing 기능을 추가한다는 것은 결국 하나의 Queue을 여러 Thread가 동시에 엑세스 할 가능성이 생긴다는 것을 의미한다. Queue를 소유한 Thread와 그 Queue에서 Work Steal을 하려는 Thread 말이다. 결국 Thread 전용으로 사용되는 Queue도 엑세스 할때 동기화 되어야 한다는 말이된다.
이렇게 되면 ThreadPool 전체에 하나의 Queue를 두고 사용하는 경우와 별반 나아질게 없다.(물론 조금은 나아지겠지만...)
처음 목표가 ThreadPool내의 Thread간에 경합과 동기화를 줄이려는 것이었는데, 이렇게 되고 보니 여전히 경합과 동기화를 피할 수 없게 된다.
ThreadPool의 Thread들에 고르게 WorkItem이 분배된 경우에는, Thread는 대부분 자신의 Queue에서만 WorkItem을 가져오기 때문에 동기화가 필요없는 경우이지만, 이때도 자신의 Queue를 엑세스 하기 위해 동기화 도구를 거쳐야만 한다.
하지만 우리에겐 또다른 무기가 있으니 바로 Lock-Free하게 구현된 Deque(Double Ended Queue)다.
Deque는 다들 알듯이, Queue와 달리 front와 end 모두에서 push와 pop이 가능한 자료구조다.
이제 Thread 전용의 Queue 대신에 Thread 전용의 Lock-Free Deque를 사용한다고 해보자.
시나리오는 이렇다.
Thread는 WorkItem이 생기면 자신의 Deque의 front에 push를 해 둔다. 그리고 자신이 WorkItem을 처리해야 할 것 같으면 Deque의 front에서 WorkItem을 pop해서 가져온다. 이 경우, Deque의 front에서 push와 pop은 하나의 Thread에 의해서만 이루어 지기 때문에 동기화가 필요없다.
그리고 다른 Thread가 해당 Thread의 Deque에서 Work Steal을 하는 경우에는 Deque의 end에서 pop을 한다. 이때 end에서 pop하는 부분을 Lock-Free하게 구현하는 것이다.
이렇게 되면 해당 Thread는 대부분 Deque의 front에서 작업이 이루어지고, 다른 Thread는 Deque의 end에서 작업이 이루어 진다.
결국 Deque안에 WorkItem이 몇개없는 상황 즉 front와 end가 가까운 경우가 아니면, 두 Thread가 경합을 벌일 경우가 현저히 줄어들게 된다.
(물론 노는 Thread가 많아서 Work Steal을 하려는 Thread들 끼리 경합이 발생할 수도 있지만, 이건 어짜피 노는 Thread들 끼리 경합이므로 그렇게 낭비라고 보기 어렵다.)
이렇게 되면 최대한 Thread의 Locality를 높이면서, 필요한 경우에도 Thread간 경합을 최소로 줄인 ThreadPool을 만들 수 있게 된다.

Intel의 TBB 나 .NET의 Parallel Extension등의 병렬 프로그래밍 라이브러리에 있는 ThreadPool은 거의 기본적으로 Work Stealing으로 구현된 ThreadPool이다.
ps)
노파심에서 덧붙이면,
ThreadPool 전체에서 하나의 Queue를 사용하는 경우라도, 이 Queue를 Lock-Free로 구현하면 간단하게 확장성을 확보할 수 있지 않을까 생각할 수 있다.
하지만 Lock-Free 자료구조라는 것이 동기화 도구를 사용하지 않도록 하여 Thread의 활동성(liveness)이 제한되는 상황, 예를 들어 Context Switch 같은 것들이 되지 않도록 하는 것일 뿐이지, 경합 자체를 줄여주는 것은 아니다. Lock-Free 자료구조라 하더라도 Thread가 많아지면 경합에 의해 손실되는 시간이 늘어나게 된다.
하지만 위에 설명한 Deque을 이용한 방법은 가능한 여러 Thread가 마주치지 않게 하는, 즉 경합자체를 줄이는 방법이라는 것을 염두해 둘 필요가 있다.
여러 코어 혹은 CPU를 활용하는 측면에서나 과도하게 Thread가 생성되는 비효율성을 줄이는 측면에서나 ThreadPool은 좋은 해답이 된다.
그러나 일반적인 ThreadPool의 구현에서도 병목이 되는 부분이 생기는데, 바로 ThreadPool에 맡겨질 WorkItem 들을 담고 있는 Queue 부분이다.
ThreadPool에 있는 여러 Thread가 하나의 Queue에서 WorkItem을 가져가려고 하는 Race Conditon이 발생하기 때문에 동기화가 필요하다. 특히 코어 혹은 CPU가 늘어나면 Thread도 그 만큼 많아지므로 경합(Contention)이 더욱 심해진다.
결국 하나의 Queue를 사용하는 ThreadPool은 확장성(scalability)이 떨어진다.
이런 경합이 발생하는 문제를 해결하는 방법은 의외로 간단할 수 있다. Queue를 하나만 사용해서 생기는 문제이기 때문에, Queue를 여러개 사용하면 된다. 즉 Thread마다 하나씩 Queue를 가질 수 있게 두는 것이다.
Thread 마다 자신의 전용 Queue를 만들어 두고, 해당 Thread에서 ThreadPool에 WorkItem을 추가하는 부분이 나오면 자신의 Queue에다가 추가해 두고, 또한 WorkItem을 처리할 때도 자신의 Queue에서 WorkItem을 가져다가 처리하게 되면 ThreadPool의 다른 Thread와 하나의 Queue를 두고 경합하는 상황을 피할 수 있다.
위 부분을 읽으면서 어렴풋이 느끼겠지만, 이건 뭔가 부족한 해결방법이다.
예를 들어 하나의 WorkItem을 처리하면 새로운 WorkItem이 여러개 생기는 형태의 작업인 경우에는, ThreadPool에 있는 Thread 중에 하나의 Thread에만 집중적으로 WorkItem이 몰리게 되는 현상이 발생하게 된다. 즉 한 Thread에는 작업이 넘쳐나는데, 다른 Thread는 놀고 있게 된다. Thread의 효율적인 활용에 문제가 생기게 되는 것이다.
이렇게 Thread 전용의 Queue를 사용함으로써 생기는 Thread간 불균형을 해결하기 위한 방법이 Work Stealing이다.
개념은 쉽다. 한 Thread가 자신의 Queue에 더이상 처리할 WorkItem이 없다면 다른 Thread의 Queue에 있는 WorkItem을 가져다가(Steal) 자신이 실행하는 것이다.
앞서 설명한 ThreadPool에 이 Work Stealing 기능을 추가하면, 혹 다른 Thread에 WorkItem이 집중되는 상황이 생기더라도, 여유가 있는 Thread가 그 WorkItem을 가져다가 실행시키게 될 것이므로 WorkItem은 비교적 공평하게 ThreadPool의 Thread들에게 분배가 된다.
따라서 확장성을 높이면서도 Thread가 비균등 현상을 해결할 수 있는 ThreadPool을 만들 수 있게 된다.
하지만...
얼핏 느낀분들도 있을거라 생각하는데, Work Stealing 기능을 추가한다는 것은 결국 하나의 Queue을 여러 Thread가 동시에 엑세스 할 가능성이 생긴다는 것을 의미한다. Queue를 소유한 Thread와 그 Queue에서 Work Steal을 하려는 Thread 말이다. 결국 Thread 전용으로 사용되는 Queue도 엑세스 할때 동기화 되어야 한다는 말이된다.
이렇게 되면 ThreadPool 전체에 하나의 Queue를 두고 사용하는 경우와 별반 나아질게 없다.(물론 조금은 나아지겠지만...)
처음 목표가 ThreadPool내의 Thread간에 경합과 동기화를 줄이려는 것이었는데, 이렇게 되고 보니 여전히 경합과 동기화를 피할 수 없게 된다.
ThreadPool의 Thread들에 고르게 WorkItem이 분배된 경우에는, Thread는 대부분 자신의 Queue에서만 WorkItem을 가져오기 때문에 동기화가 필요없는 경우이지만, 이때도 자신의 Queue를 엑세스 하기 위해 동기화 도구를 거쳐야만 한다.
하지만 우리에겐 또다른 무기가 있으니 바로 Lock-Free하게 구현된 Deque(Double Ended Queue)다.
Deque는 다들 알듯이, Queue와 달리 front와 end 모두에서 push와 pop이 가능한 자료구조다.
이제 Thread 전용의 Queue 대신에 Thread 전용의 Lock-Free Deque를 사용한다고 해보자.
시나리오는 이렇다.
Thread는 WorkItem이 생기면 자신의 Deque의 front에 push를 해 둔다. 그리고 자신이 WorkItem을 처리해야 할 것 같으면 Deque의 front에서 WorkItem을 pop해서 가져온다. 이 경우, Deque의 front에서 push와 pop은 하나의 Thread에 의해서만 이루어 지기 때문에 동기화가 필요없다.
그리고 다른 Thread가 해당 Thread의 Deque에서 Work Steal을 하는 경우에는 Deque의 end에서 pop을 한다. 이때 end에서 pop하는 부분을 Lock-Free하게 구현하는 것이다.
이렇게 되면 해당 Thread는 대부분 Deque의 front에서 작업이 이루어지고, 다른 Thread는 Deque의 end에서 작업이 이루어 진다.
결국 Deque안에 WorkItem이 몇개없는 상황 즉 front와 end가 가까운 경우가 아니면, 두 Thread가 경합을 벌일 경우가 현저히 줄어들게 된다.
(물론 노는 Thread가 많아서 Work Steal을 하려는 Thread들 끼리 경합이 발생할 수도 있지만, 이건 어짜피 노는 Thread들 끼리 경합이므로 그렇게 낭비라고 보기 어렵다.)
이렇게 되면 최대한 Thread의 Locality를 높이면서, 필요한 경우에도 Thread간 경합을 최소로 줄인 ThreadPool을 만들 수 있게 된다.
Intel의 TBB 나 .NET의 Parallel Extension등의 병렬 프로그래밍 라이브러리에 있는 ThreadPool은 거의 기본적으로 Work Stealing으로 구현된 ThreadPool이다.
ps)
노파심에서 덧붙이면,
ThreadPool 전체에서 하나의 Queue를 사용하는 경우라도, 이 Queue를 Lock-Free로 구현하면 간단하게 확장성을 확보할 수 있지 않을까 생각할 수 있다.
하지만 Lock-Free 자료구조라는 것이 동기화 도구를 사용하지 않도록 하여 Thread의 활동성(liveness)이 제한되는 상황, 예를 들어 Context Switch 같은 것들이 되지 않도록 하는 것일 뿐이지, 경합 자체를 줄여주는 것은 아니다. Lock-Free 자료구조라 하더라도 Thread가 많아지면 경합에 의해 손실되는 시간이 늘어나게 된다.
하지만 위에 설명한 Deque을 이용한 방법은 가능한 여러 Thread가 마주치지 않게 하는, 즉 경합자체를 줄이는 방법이라는 것을 염두해 둘 필요가 있다.
Multi Threading
* 2005년 DDJ의 공짜 점심의 끝 : http://www.ddj.com/web-development/184405990 - 한글요약(http://rein.upnl.org/wordpress/archives/540)
* 2007년 DDJ의 "얼마나 확장가능한가, 혹은 확장할 필요가 있는가?" : http://www.ddj.com/hpc-high-performance-computing/201202924
* 2007년 DDJ의 "동시성 프로그램의 분류(Pillars of Concurrency)" : http://www.ddj.com/hpc-high-performance-computing/200001985
* 2008년 DDJ의 "암달의 법칙 깨기 (Breaking the Amdahl's Law)" : http://www.ddj.com/architect/205900309 - 한글요약(http://rein.upnl.org/wordpress/archives/541)
* 2007년 DDJ의 "얼마나 확장가능한가, 혹은 확장할 필요가 있는가?" : http://www.ddj.com/hpc-high-performance-computing/201202924
* 2007년 DDJ의 "동시성 프로그램의 분류(Pillars of Concurrency)" : http://www.ddj.com/hpc-high-performance-computing/200001985
* 2008년 DDJ의 "암달의 법칙 깨기 (Breaking the Amdahl's Law)" : http://www.ddj.com/architect/205900309 - 한글요약(http://rein.upnl.org/wordpress/archives/541)
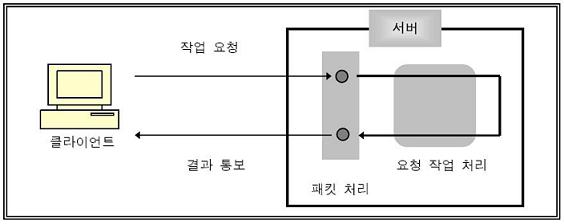
epoll, worker thread를 이용한 chatting server
http://chonga.pe.kr/blog/index.php?pl=972&ct1=31&ct2=62
요즘 초보자를 위한 시리즈로 몇 가지 리눅스 강좌를 하면서 학생들에게 숙제를 내긴 했는데, 해답이 없으면 뭐해서 직접 간단히 해답을 만들어 보았다. 숙제는 linux의 최근에 안정화된 것으로 보이는 network i/o model인 epoll을 이용해서 edge triggered model의 oneshot flag를 설정하고 패킷의 읽기 처리를 다른 worker thread에서 하는 채팅서버를 구현하라는 것이었다. 또한 반드시 thread cancellation을 이용해서 쓰레드를 종료하도록 숙제를 내었는데, 이는 pthread의 condition 관련 함수에서는 cancellation 영역을 제대로 처리해주지 못할 수도 있어서 스스로 해결책을 찾아볼 수 있도록 준비했다나 뭐라나.. 2001년 6월의 Linux High Performance Server 기사와 2003년 4월에 event poll, rtsignal로 간단히 테스트해보고 작성했던 기사 Linux Network Engine for Online Game 이후에 2007년 들어서 리눅스 강좌와 더불어 실로 epoll도 오랜만의 포스팅인 듯 하다.
----
1 개요
2 채팅 서버의 설명
2.1 기본 파일 설명
2.2 호출 관계 그래프
2.3 main(chatserver.cpp) 함수에서 하는 일
2.4 cchatmgr 클래스(chatmgr.cpp)에 대해
2.5 userlist와 user정보
2.6 worker thread와 workerjobqueue에 대해
2.7 network 관련 유틸리티에 대해
3 프로그램의 실행
3.1 서버 실행
3.2 첫번째 클라이언트 실행 (소켓 번호 5번으로 접속됨)
3.3 두번째 클라이언트 실행 (소켓 번호 6번으로 접속됨)
3.4 서버 종료
----
1 개요
Linux Programming에서도 새로운 network io model인 epoll의 edge-triggered의 one-shot 모델을 기반으로 소켓 읽기 부분을 worker thread에서 처리할 수 있도록 채팅서버의 예제를 구성해보고 간단한 설명을 하려고 한다. 성능이나 설계면에서 부족한 부분이나 stl의 자료 구조를 다양하게 이용해본 측면도 있으므로 그 부분은 감안하고 예제를 참고해주기를 바란다.
이 예제는 centos 4.4의 기본 환경에서 테스트 되었다.
2 채팅 서버의 설명
2.1 기본 파일 설명
◆ 소스 다운 로드 : linux-chatting-server-example-by-leehongki-20071129.zip
2.2 호출 관계 그래프
main함수로부터 어떻게 호출되는 관계인지 전체 그래프를 아래와 같이 볼 수 있다. 아래 그림을 클릭하면 확대된 그림을 확인할 수 있다.
chatserver의 호출관계 그래프
2.3 main(chatserver.cpp) 함수에서 하는 일
한마디로 간단하게 설명하면 서버를 기동하고 정지하는 기능이 구현되어 있다. 즉 구체적으로는 다음과 같은 일을 한다.
enter key를 누르면 정상적으로 셧다운을 시키기 위해서 쓰레드를 종료시키고 자원을 해제하고 난 후에 exit가 호출되고 종료된다.
2.4 cchatmgr 클래스(chatmgr.cpp)에 대해
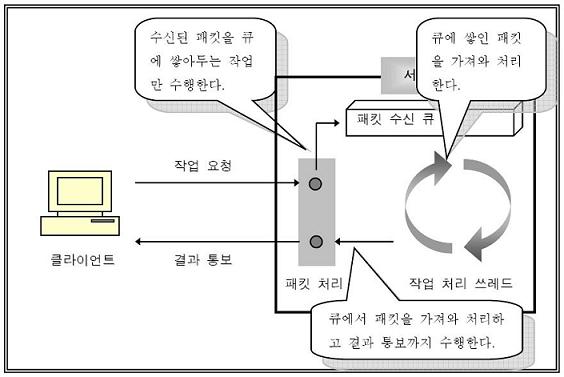
main함수로부터 클래스가 생성되면, stl의 list로 작성된 userlist와 threadpool 등이 초기화된다. start() 함수가 호출되면서부터 크게 2가지 종류의 쓰레드가 초기화된다. 첫번째 종류의 쓰레드는 accept socket을 생성하여 사용자로부터 소켓 접속을 받을 수 있도록 준비하고 epoll 관련 함수들이 초기화된다. 마지막으로는 epoll의 epoll_wait의 루프문으로 무한루프를 수행하게 된다. 이 루프에서 하는 일은 accept socket을 감시하여 새로운 사용자를 추가하거나 사용자로부터의 입력이 있을 경우에 입력 이벤트를 workerjobqueue에 넣어주는 일을 하게된다. 두번째 종류의 쓰레드는 worker thread로 기본값으로 3개의 쓰레드가 기동되어 workerjobqueue에 들어온 이벤트가 있을 때마다 깨어나 패킷을 읽고 채팅 메시지를 파싱하여 주변 클라이언트에게 전송해주는 일을 해준다.
2.5 userlist와 user정보
cmutex class를 상속받은 cuserlist 클래스에는 cuser를 원소로 갖는 list가 존재한다. 이 리스트는 cchatmgr의 인스턴스의 생성과 함께 초기화된다. 이후에 사용자가 새로 접속하면 cuser가 하나 생성되고 소켓이 끊기면 메모리에서 삭제된다.
cuser class 의 역할은 말그대로 사용자 정보를 담고 있는데 client의 socket id 등의 정보와 함께 socket buffer를 stl vector로 구현한 원형큐로서 enqueue와 dequeue 관련 함수들이 마련되어 있다. 여기서는 dequeue를 하는 경우에 간단한 채팅 패킷을 파싱해주기도 한다. 파싱을 하기위해서 구분자를 '\n'을 ENDMARK로 인식하게 하는데, cuser의 settextprotocol(true)로 초기화해주면 파싱 기능을 이용할 수 있도록 하였다. 이 클래스를 좀더 확장하여 사용자의 이름 등의 정보를 담을 수도 있다. 설계의 문제겠지만 때에 따라서는 버퍼 및 프로토콜의 처리 부분은 이 클래스에서 분리하는 방법도 생각할 수 있다. cuserlist와 마찬가지로 cmutex로부터 상속받아 자원의 보호를 수행한다.
2.6 worker thread와 workerjobqueue에 대해
worker thread도 다른 객체들과 마찬가지로 ccharmgr가 생성될 때 함께 초기화된다. 다만, cchatmgr의 인스턴스의 start()가 호출되면서 실제 worker thread의 생성이 이루어진다. setthreadfuncptr을 통해서 workerthread의 쓰레드 함수를 지정할 수 있는데, 여기서는 epoll_wait에서 감지된 클라이언트의 소켓 읽기 이벤트를 workerjobqueue로부터 가져와서 ccharmgr의 handlefd() 함수에서 실제로 채팅 메시지 읽어오기와 주변 클라이언트로 패킷을 전송하는 기능을 수행하게 된다. workerjobqueue는 이벤트 감지시에 여러 쓰레드 중에 단 1개의 쓰레드만 깨어나서 수행하게 된다. 현재 worker thread의 개수는 3개로 잡아두었다.
workerjobqueue는 stl의 queue로 FIFO(First In First Out) 구조로 수행된다. 내부적으로 mutex와 condition을 갖고 있어, epoll_wait가 수행되는 쓰레드에서는 queue에 push를 수행하면서 동시에 signal을 발생시킨다. worker thread의 쓰레드 루프에서는 condition wait를 하고 있는데, signal을 받으면 대기중인 쓰레드 중에 단 하나만이 깨어나서 처리한다. 대기하고 있는 모든 worker thread가 깨어날 수 있도록 broadcast() 함수도 지원한다. 이는 프로그램 종료시에 사용하고 있다.
worker thread에서 종료시에 pthread의 cancellation을 사용하는 곳에 문제가 있는데, pthread_cond_* 함수의 경우에 여러 쓰레드가 대기하고 있는 경우에 cancellation 시그널을 단 하나만 받게되는 것 같다. 이에 대한 해결책은 여러가지가 있겠지만, 여기서는 broadcast를 해서 모든 쓰레드를 깨우고, 그 때에 리턴한 값에 서버 종료에 대한 값을 넣어서 처리했다.
condition관련 기능을 사용할 때에, 주의할 점은 pthread_cond_signal로 발송한 시그널을 보장할 수 없는 경우가 생길 수 있다는 점인데, pthread_cond_wait의 쓰레드에서 완벽하게 wait 상태로 진입하지 않은 상태에서는 skip될 수가 있다. 이 부분에 대한 처리도 고려해야한다.
2.7 network 관련 유틸리티에 대해
network.cpp를 보게되면 epoll 및 각종 소켓 서버를 위한 유틸리티들이 존재하고 있다. 구체적으로는 다음과 같다. NON BLOCKING SOCKET 설정, TCPNODELAY설정, REUSEADDR설정을 위한 함수와 epoll관련한 Wrapper 함수들이다. cchatmgr 클래스에서 적절히 사용하고 있다.
socket 프로그래밍을 할 때에 또 한가지 빠뜨려서는 안될 것이 있는데 SIG_PIPE의 signal을 무시해야한다. 보통 소켓 프로그램에서는 SIG_PIPE가 종종 비주기적으로 발생하는데, SIG_PIPE를 받으면 일반적으로 프로그램이 종료되어 버린다. 소켓 서버를 처음 만드는 사람을 당황하게 만든다. gdb와 같은 디버거로 실행시켜보면, SIG_PIPE로 인해 프로그램이 종료되는 것을 확인해볼 수 있다. 때문에 이를 방지하기 위해서 cchatmgr의 epoll 관련 초기화 함수에 signal (SIGPIPE, SIG_IGN)가 설정되어 있다.
마지막으로, 이 예제에서 비동기 소켓을 사용하기 때문에 recv의 경우에는 WOULD_BLOCK을 처리해주도록 했는데, send 할 때에도 가급적 송신용 버퍼를 마련해두고 마찬가지로 nonblocking에서의 처리를 해줘야한다. 우선은 채팅 예제이기 때문에 빠져있는데 상용 어플리케이션에서는 주의해야한다. epoll의 경우 EPOLL_CTL_ADD시에 EPOLLIN|EPOLLOUT을 양쪽다 지정해주고 EPOLLOUT 이벤트가 발생하면 송신 버퍼에서 꺼내어 전송해주는 부분은 숙제로 남겨두기로 한다.
3 프로그램의 실행
3.1 서버 실행
makefile을 이용해 make 명령으로 빌드를 하면 chatserver 라는 이름의 바이너리가 생성된다. 첫번째 인자를 server port로 인식한다. 다음과 같이 press 'enter' key to shutdown가 나오면 서버가 정상적으로 수행된 것이다. enter key를 누르면 서버는 자동으로 종료된다.
3.2 첫번째 클라이언트 실행 (소켓 번호 5번으로 접속됨)
클라이언트는 일반 telnet 프로그램을 이용하도록 했다. 아래는 첫번째 클라이언트를 띄웠다. localhost로 접속해서 socket id 5번이 되었다. hello i am hongki 로부터 시작했다. 2번째로 접속한 클라이언트가 접속을 해제했는데, "6 is connection closed"라는 공지 메시지가 발송된다.
3.3 두번째 클라이언트 실행 (소켓 번호 6번으로 접속됨)
3.4 서버 종료
CHATSERVER 0.1 - test example (c)orinmir / build date: May 2 2007
! listening port : 4444
! server started
! press 'enter' key to shutdown.
! stop application.
! cthreadpool::stop() - picked up thread
! cthreadpool::stop() - picked up thread
! cthreadpool::stop() - picked up thread
! cchatmgr::stopnetwork - picked up thread
4. 참고 자료
- linux epoll server example : http://chonga.pe.kr/blog/index.php?pl=919
- epoll, poll, select 성능 분석
요즘 초보자를 위한 시리즈로 몇 가지 리눅스 강좌를 하면서 학생들에게 숙제를 내긴 했는데, 해답이 없으면 뭐해서 직접 간단히 해답을 만들어 보았다. 숙제는 linux의 최근에 안정화된 것으로 보이는 network i/o model인 epoll을 이용해서 edge triggered model의 oneshot flag를 설정하고 패킷의 읽기 처리를 다른 worker thread에서 하는 채팅서버를 구현하라는 것이었다. 또한 반드시 thread cancellation을 이용해서 쓰레드를 종료하도록 숙제를 내었는데, 이는 pthread의 condition 관련 함수에서는 cancellation 영역을 제대로 처리해주지 못할 수도 있어서 스스로 해결책을 찾아볼 수 있도록 준비했다나 뭐라나.. 2001년 6월의 Linux High Performance Server 기사와 2003년 4월에 event poll, rtsignal로 간단히 테스트해보고 작성했던 기사 Linux Network Engine for Online Game 이후에 2007년 들어서 리눅스 강좌와 더불어 실로 epoll도 오랜만의 포스팅인 듯 하다.
◆ 오랜만의 리눅스 강좌 목록
Linux 강좌 #3 : epoll, worker thread를 이용한 chatting server
Linux 강좌 #2 : linux epoll을 이용한 echo server
Linux 강좌 #1 : Linux와 Linux개발환경의 이해
Linux 강좌 #3 : epoll, worker thread를 이용한 chatting server
Linux 강좌 #2 : linux epoll을 이용한 echo server
Linux 강좌 #1 : Linux와 Linux개발환경의 이해
- 작성자: 어린미르 (orinmir _at_ gmail.com)
- 문서 위치: http://chonga.pe.kr/blog/index.php?pl=972
- 작성일: 20070502
- 문서 변경 이력 :
20070502 초판 릴리즈
20070507 수정판 릴리즈
20070510 worker thread의 종료에 대한 설명 추가
20070518 example code에 null 처리 안한 부분 추가
20071129 accept, waitpop관련 버그 수정, 소스 갱신 업데이트
선언: 본 문서는 저자의 개인적인 의견이 있을 수 있습니다. 이 곳에 게재된 내용은 상업적 판단을 위한 자료로 이용될 수 없으며 그로 인한 책임은 저자에게 없습니다.
- 문서 위치: http://chonga.pe.kr/blog/index.php?pl=972
- 작성일: 20070502
- 문서 변경 이력 :
20070502 초판 릴리즈
20070507 수정판 릴리즈
20070510 worker thread의 종료에 대한 설명 추가
20070518 example code에 null 처리 안한 부분 추가
20071129 accept, waitpop관련 버그 수정, 소스 갱신 업데이트
선언: 본 문서는 저자의 개인적인 의견이 있을 수 있습니다. 이 곳에 게재된 내용은 상업적 판단을 위한 자료로 이용될 수 없으며 그로 인한 책임은 저자에게 없습니다.
----
1 개요
2 채팅 서버의 설명
2.1 기본 파일 설명
2.2 호출 관계 그래프
2.3 main(chatserver.cpp) 함수에서 하는 일
2.4 cchatmgr 클래스(chatmgr.cpp)에 대해
2.5 userlist와 user정보
2.6 worker thread와 workerjobqueue에 대해
2.7 network 관련 유틸리티에 대해
3 프로그램의 실행
3.1 서버 실행
3.2 첫번째 클라이언트 실행 (소켓 번호 5번으로 접속됨)
3.3 두번째 클라이언트 실행 (소켓 번호 6번으로 접속됨)
3.4 서버 종료
----
1 개요
Linux Programming에서도 새로운 network io model인 epoll의 edge-triggered의 one-shot 모델을 기반으로 소켓 읽기 부분을 worker thread에서 처리할 수 있도록 채팅서버의 예제를 구성해보고 간단한 설명을 하려고 한다. 성능이나 설계면에서 부족한 부분이나 stl의 자료 구조를 다양하게 이용해본 측면도 있으므로 그 부분은 감안하고 예제를 참고해주기를 바란다.
이 예제는 centos 4.4의 기본 환경에서 테스트 되었다.
2 채팅 서버의 설명
2.1 기본 파일 설명
◆ 소스 다운 로드 : linux-chatting-server-example-by-leehongki-20071129.zip
chatdefine.h : 각종 정의
chatmgr.cpp : 채팅 서버의 메인 모듈
chatmgr.h
chatserver.cpp : 채팅 서버의 시작점
makefile : 빌드 스크립트
network.cpp : 소켓 관련 유틸리티
network.h
thread.cpp : 쓰레드 풀, 뮤텍스, 워커쓰레드용 큐
thread.h
user.cpp : 사용자 객체의 정의, 사용자목록관리자
user.h
chatmgr.cpp : 채팅 서버의 메인 모듈
chatmgr.h
chatserver.cpp : 채팅 서버의 시작점
makefile : 빌드 스크립트
network.cpp : 소켓 관련 유틸리티
network.h
thread.cpp : 쓰레드 풀, 뮤텍스, 워커쓰레드용 큐
thread.h
user.cpp : 사용자 객체의 정의, 사용자목록관리자
user.h
2.2 호출 관계 그래프
main함수로부터 어떻게 호출되는 관계인지 전체 그래프를 아래와 같이 볼 수 있다. 아래 그림을 클릭하면 확대된 그림을 확인할 수 있다.
 |
2.3 main(chatserver.cpp) 함수에서 하는 일
한마디로 간단하게 설명하면 서버를 기동하고 정지하는 기능이 구현되어 있다. 즉 구체적으로는 다음과 같은 일을 한다.
- 첫번째 인수로부터 서버 port 받아오기
- cchatmgr 객체의 인스턴스 생성
- cchatmgr 인스턴스에 port 설정
- cchatmgr->start() 로 서버 기동
- 표준입력(stdin)으로부터 enter key의 입력를 기다림
- enter key의 입력이 있을 때까지 서버 기동 상태
- cchatmgr 객체의 인스턴스 생성
- cchatmgr 인스턴스에 port 설정
- cchatmgr->start() 로 서버 기동
- 표준입력(stdin)으로부터 enter key의 입력를 기다림
- enter key의 입력이 있을 때까지 서버 기동 상태
enter key를 누르면 정상적으로 셧다운을 시키기 위해서 쓰레드를 종료시키고 자원을 해제하고 난 후에 exit가 호출되고 종료된다.
2.4 cchatmgr 클래스(chatmgr.cpp)에 대해
main함수로부터 클래스가 생성되면, stl의 list로 작성된 userlist와 threadpool 등이 초기화된다. start() 함수가 호출되면서부터 크게 2가지 종류의 쓰레드가 초기화된다. 첫번째 종류의 쓰레드는 accept socket을 생성하여 사용자로부터 소켓 접속을 받을 수 있도록 준비하고 epoll 관련 함수들이 초기화된다. 마지막으로는 epoll의 epoll_wait의 루프문으로 무한루프를 수행하게 된다. 이 루프에서 하는 일은 accept socket을 감시하여 새로운 사용자를 추가하거나 사용자로부터의 입력이 있을 경우에 입력 이벤트를 workerjobqueue에 넣어주는 일을 하게된다. 두번째 종류의 쓰레드는 worker thread로 기본값으로 3개의 쓰레드가 기동되어 workerjobqueue에 들어온 이벤트가 있을 때마다 깨어나 패킷을 읽고 채팅 메시지를 파싱하여 주변 클라이언트에게 전송해주는 일을 해준다.
2.5 userlist와 user정보
cmutex class를 상속받은 cuserlist 클래스에는 cuser를 원소로 갖는 list가 존재한다. 이 리스트는 cchatmgr의 인스턴스의 생성과 함께 초기화된다. 이후에 사용자가 새로 접속하면 cuser가 하나 생성되고 소켓이 끊기면 메모리에서 삭제된다.
cuser class 의 역할은 말그대로 사용자 정보를 담고 있는데 client의 socket id 등의 정보와 함께 socket buffer를 stl vector로 구현한 원형큐로서 enqueue와 dequeue 관련 함수들이 마련되어 있다. 여기서는 dequeue를 하는 경우에 간단한 채팅 패킷을 파싱해주기도 한다. 파싱을 하기위해서 구분자를 '\n'을 ENDMARK로 인식하게 하는데, cuser의 settextprotocol(true)로 초기화해주면 파싱 기능을 이용할 수 있도록 하였다. 이 클래스를 좀더 확장하여 사용자의 이름 등의 정보를 담을 수도 있다. 설계의 문제겠지만 때에 따라서는 버퍼 및 프로토콜의 처리 부분은 이 클래스에서 분리하는 방법도 생각할 수 있다. cuserlist와 마찬가지로 cmutex로부터 상속받아 자원의 보호를 수행한다.
2.6 worker thread와 workerjobqueue에 대해
worker thread도 다른 객체들과 마찬가지로 ccharmgr가 생성될 때 함께 초기화된다. 다만, cchatmgr의 인스턴스의 start()가 호출되면서 실제 worker thread의 생성이 이루어진다. setthreadfuncptr을 통해서 workerthread의 쓰레드 함수를 지정할 수 있는데, 여기서는 epoll_wait에서 감지된 클라이언트의 소켓 읽기 이벤트를 workerjobqueue로부터 가져와서 ccharmgr의 handlefd() 함수에서 실제로 채팅 메시지 읽어오기와 주변 클라이언트로 패킷을 전송하는 기능을 수행하게 된다. workerjobqueue는 이벤트 감지시에 여러 쓰레드 중에 단 1개의 쓰레드만 깨어나서 수행하게 된다. 현재 worker thread의 개수는 3개로 잡아두었다.
workerjobqueue는 stl의 queue로 FIFO(First In First Out) 구조로 수행된다. 내부적으로 mutex와 condition을 갖고 있어, epoll_wait가 수행되는 쓰레드에서는 queue에 push를 수행하면서 동시에 signal을 발생시킨다. worker thread의 쓰레드 루프에서는 condition wait를 하고 있는데, signal을 받으면 대기중인 쓰레드 중에 단 하나만이 깨어나서 처리한다. 대기하고 있는 모든 worker thread가 깨어날 수 있도록 broadcast() 함수도 지원한다. 이는 프로그램 종료시에 사용하고 있다.
worker thread에서 종료시에 pthread의 cancellation을 사용하는 곳에 문제가 있는데, pthread_cond_* 함수의 경우에 여러 쓰레드가 대기하고 있는 경우에 cancellation 시그널을 단 하나만 받게되는 것 같다. 이에 대한 해결책은 여러가지가 있겠지만, 여기서는 broadcast를 해서 모든 쓰레드를 깨우고, 그 때에 리턴한 값에 서버 종료에 대한 값을 넣어서 처리했다.
condition관련 기능을 사용할 때에, 주의할 점은 pthread_cond_signal로 발송한 시그널을 보장할 수 없는 경우가 생길 수 있다는 점인데, pthread_cond_wait의 쓰레드에서 완벽하게 wait 상태로 진입하지 않은 상태에서는 skip될 수가 있다. 이 부분에 대한 처리도 고려해야한다.
2.7 network 관련 유틸리티에 대해
network.cpp를 보게되면 epoll 및 각종 소켓 서버를 위한 유틸리티들이 존재하고 있다. 구체적으로는 다음과 같다. NON BLOCKING SOCKET 설정, TCPNODELAY설정, REUSEADDR설정을 위한 함수와 epoll관련한 Wrapper 함수들이다. cchatmgr 클래스에서 적절히 사용하고 있다.
int setnonblock (int sock);
int settcpnodelay (int sock);
int setreuseaddr (int sock);
int init_epoll (int eventsize);
int init_acceptsock (unsigned short port);
int do_accept (int efd, int sfd);
int add_epollfd (int efd, int cfd, bool useoneshot = true);
int modify_epollfd (int efd, int cfd, bool useoneshot = true);
int del_epollfd (int efd, int cfd);
int settcpnodelay (int sock);
int setreuseaddr (int sock);
int init_epoll (int eventsize);
int init_acceptsock (unsigned short port);
int do_accept (int efd, int sfd);
int add_epollfd (int efd, int cfd, bool useoneshot = true);
int modify_epollfd (int efd, int cfd, bool useoneshot = true);
int del_epollfd (int efd, int cfd);
socket 프로그래밍을 할 때에 또 한가지 빠뜨려서는 안될 것이 있는데 SIG_PIPE의 signal을 무시해야한다. 보통 소켓 프로그램에서는 SIG_PIPE가 종종 비주기적으로 발생하는데, SIG_PIPE를 받으면 일반적으로 프로그램이 종료되어 버린다. 소켓 서버를 처음 만드는 사람을 당황하게 만든다. gdb와 같은 디버거로 실행시켜보면, SIG_PIPE로 인해 프로그램이 종료되는 것을 확인해볼 수 있다. 때문에 이를 방지하기 위해서 cchatmgr의 epoll 관련 초기화 함수에 signal (SIGPIPE, SIG_IGN)가 설정되어 있다.
마지막으로, 이 예제에서 비동기 소켓을 사용하기 때문에 recv의 경우에는 WOULD_BLOCK을 처리해주도록 했는데, send 할 때에도 가급적 송신용 버퍼를 마련해두고 마찬가지로 nonblocking에서의 처리를 해줘야한다. 우선은 채팅 예제이기 때문에 빠져있는데 상용 어플리케이션에서는 주의해야한다. epoll의 경우 EPOLL_CTL_ADD시에 EPOLLIN|EPOLLOUT을 양쪽다 지정해주고 EPOLLOUT 이벤트가 발생하면 송신 버퍼에서 꺼내어 전송해주는 부분은 숙제로 남겨두기로 한다.
3 프로그램의 실행
3.1 서버 실행
makefile을 이용해 make 명령으로 빌드를 하면 chatserver 라는 이름의 바이너리가 생성된다. 첫번째 인자를 server port로 인식한다. 다음과 같이 press 'enter' key to shutdown가 나오면 서버가 정상적으로 수행된 것이다. enter key를 누르면 서버는 자동으로 종료된다.
[orinmir@chonga chatserver]$ ./chatserver 4444
CHATSERVER 0.1 - test example (c)orinmir / build date: May 2 2007
! listening port : 4444
! server started
! press 'enter' key to shutdown.
! client closed - end of file detected - fd 6
CHATSERVER 0.1 - test example (c)orinmir / build date: May 2 2007
! listening port : 4444
! server started
! press 'enter' key to shutdown.
! client closed - end of file detected - fd 6
3.2 첫번째 클라이언트 실행 (소켓 번호 5번으로 접속됨)
클라이언트는 일반 telnet 프로그램을 이용하도록 했다. 아래는 첫번째 클라이언트를 띄웠다. localhost로 접속해서 socket id 5번이 되었다. hello i am hongki 로부터 시작했다. 2번째로 접속한 클라이언트가 접속을 해제했는데, "6 is connection closed"라는 공지 메시지가 발송된다.
[orinmir@chonga homework]$ telnet localhost 4444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
hello i am hongki
[ 5]:hello i am hongki
[ 6]:hi! this is orinmir
[ 6]:i am gonna go out now. see ya
[notice]: 6 is connection closed
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
hello i am hongki
[ 5]:hello i am hongki
[ 6]:hi! this is orinmir
[ 6]:i am gonna go out now. see ya
[notice]: 6 is connection closed
3.3 두번째 클라이언트 실행 (소켓 번호 6번으로 접속됨)
[orinmir@chonga homework]$ telnet localhost 4444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
hi! this is orinmir
[ 6]:hi! this is orinmir
i am gonna go out now. see ya
[ 6]:i am gonna go out now. see ya
^]
telnet> close
Connection closed.
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
hi! this is orinmir
[ 6]:hi! this is orinmir
i am gonna go out now. see ya
[ 6]:i am gonna go out now. see ya
^]
telnet> close
Connection closed.
3.4 서버 종료
CHATSERVER 0.1 - test example (c)orinmir / build date: May 2 2007
! listening port : 4444
! server started
! press 'enter' key to shutdown.
! stop application.
! cthreadpool::stop() - picked up thread
! cthreadpool::stop() - picked up thread
! cthreadpool::stop() - picked up thread
! cchatmgr::stopnetwork - picked up thread
4. 참고 자료
- linux epoll server example : http://chonga.pe.kr/blog/index.php?pl=919
- epoll, poll, select 성능 분석
소켓 입출력 모델의 장단점(비교)
■ 각 모델들의 장점
Select 모델
- 모든 윈도우 버전은 물론 유닉스에서도 사용할 수 있으므로 이식성이 높다.
WSAAsyncSelect 모델
- 소켓 이벤트를 윈도우 메시지 형태로 처리하므로, GUI 애플리케이션과 잘 결합 할 수 있다.
WSAEventSelect 모델
- Select 모델과 WSAAsyncSelect 모델의 특성을 혼합한 형태로, 비교적 뛰어난 성능을 제공하면서 윈도우를 필요로 하지 않는다.
Overlapped 모델(Ⅰ)
- WSAEventSelect 모델과 비슷하지만 비동기 입출력을 통해 성능이 뛰어나다.
Overlapped 모델(Ⅱ)
- 비동기 입출력을 통해 성능이 뛰어나다. ( APC Queue )
Comlpetion Port 모델 ( IOCP )
- 비동기 입출력과 완료포트를 통해 가장 뛰어난 성능을 제공한다.
■ 각 모델들의 단점
Select 모델
- 하위 호환성을 위해 존재하며, 성능은 여섯 가지 모델 중 가장 떨어진다.
64개 이상의 소켓을 처리하려면 여러개의 스레드를 사용해야 한다.
WSAAsyncSelect 모델
- 하나의 윈도우 프로시저에서 일반 윈도우 메시지와 소켓 메시지를 처리해야 하므로 성능저하의 요인이 된다.
WSAEventSelect 모델
- 64개 이상의 소켓을 처리하려면 여러 개의 스레드를 사용해야 한다.
Overlapped 모델(Ⅰ)
- 64개 이상의 소켓을 처리하려면 여러 개의 스레드를 사용해야 한다.
Overlapped 모델(Ⅱ)
- 모든 비동기 소켓 함수에 대해 완료 루틴을 사용 할 수 있는 것은 아니다.
Comlpetion Port 모델
- 가장 단순한 소켓 입출력 방식( 블로킹 소켓 + 스레드 )와 비교하면 코딩이 복잡하지만 성능면에서 특별한 단점이 없다.
윈도우 NT계열에서만 사용할 수 있다.
■ 동기 입출력과 비동기 입출력 모델의 성능
Select, WSAAsyncSelect, WSAEventSelect
- 동기 입출력을 사용하므로 성능면에서 비동기 입출력 모델에 비해서 떨어진다.
Overlapped(Ⅰ), Overlapped(Ⅱ), Comlpetion Port (IOCP)
- 비동기 입출력을 사용하므로 성능이 높다.
■ 소켓 입출력 모델이 요구되는 사항
1. 소켓 함수 호출 시 블로킹을 최소화한다.
여섯가지 모델 모두 만족한다.
2. 입출력 작업을 다른 작업과 병행한다.
비동기 입출력 방식을 사용하는 Overlapped 모델(Ⅰ), Overlapped 모델(Ⅱ), Comlpetion Port 모델만 만족한다.
3. 스레드 개수를 최소화한다.
여섯가지 모델 모두 어느정도 만족한다.
64개 이상의 소켓을 만들시에는 WSAAsyncSelect 모델, Overlapped 모델(Ⅱ), Comlpetion Port 모델을 제외하고는
스레드를 추가로 생성한다.
하지만 WSAAsyncSelect 모델은 스레드 개수가 늘어나면 성능이 상당히 떨어져서 Overlapped 모델(Ⅱ), Comlpetion Port 모델만
이 조건을 만족한다. ( IOCP는 CPU 개수에 비례하여 작업자 스레드를 생성할 수 있으므로 가장 이상적이다. )
4. 유저모드와 커널모드 전환 횟수와 데이터 복사를 최소화한다.
비동기 입출력 방식을 사용하는 모델만 이 조건을 만족한다.
비동기 입출력을 할대 송신버퍼나 수신버퍼가 가득차면, 윈도우 운영체제는 애플리케이션 버퍼를 잠근후(lock),
이 메모리 영역을 직접 접근한다.
따라서 유저영역 ↔ 커널 영역 복사가 불필요하며 모드 전환없이 입출력 작업을 곧바로 이루므로 효율적이다.
※ 결론은 위의 모든 조건을 만족하는 모델은 Overlapped 모델(Ⅱ)과 IOCP 모델뿐이다.
하지만 성능 면에서 IOCP가 좋기 때문에 거의 모든 Server는 IOCP로 만든다.( 그 이외의 것을 사용한다는 소리는 들은 적이 없다. )
Select 모델
- 모든 윈도우 버전은 물론 유닉스에서도 사용할 수 있으므로 이식성이 높다.
WSAAsyncSelect 모델
- 소켓 이벤트를 윈도우 메시지 형태로 처리하므로, GUI 애플리케이션과 잘 결합 할 수 있다.
WSAEventSelect 모델
- Select 모델과 WSAAsyncSelect 모델의 특성을 혼합한 형태로, 비교적 뛰어난 성능을 제공하면서 윈도우를 필요로 하지 않는다.
Overlapped 모델(Ⅰ)
- WSAEventSelect 모델과 비슷하지만 비동기 입출력을 통해 성능이 뛰어나다.
Overlapped 모델(Ⅱ)
- 비동기 입출력을 통해 성능이 뛰어나다. ( APC Queue )
Comlpetion Port 모델 ( IOCP )
- 비동기 입출력과 완료포트를 통해 가장 뛰어난 성능을 제공한다.
■ 각 모델들의 단점
Select 모델
- 하위 호환성을 위해 존재하며, 성능은 여섯 가지 모델 중 가장 떨어진다.
64개 이상의 소켓을 처리하려면 여러개의 스레드를 사용해야 한다.
WSAAsyncSelect 모델
- 하나의 윈도우 프로시저에서 일반 윈도우 메시지와 소켓 메시지를 처리해야 하므로 성능저하의 요인이 된다.
WSAEventSelect 모델
- 64개 이상의 소켓을 처리하려면 여러 개의 스레드를 사용해야 한다.
Overlapped 모델(Ⅰ)
- 64개 이상의 소켓을 처리하려면 여러 개의 스레드를 사용해야 한다.
Overlapped 모델(Ⅱ)
- 모든 비동기 소켓 함수에 대해 완료 루틴을 사용 할 수 있는 것은 아니다.
Comlpetion Port 모델
- 가장 단순한 소켓 입출력 방식( 블로킹 소켓 + 스레드 )와 비교하면 코딩이 복잡하지만 성능면에서 특별한 단점이 없다.
윈도우 NT계열에서만 사용할 수 있다.
■ 동기 입출력과 비동기 입출력 모델의 성능
Select, WSAAsyncSelect, WSAEventSelect
- 동기 입출력을 사용하므로 성능면에서 비동기 입출력 모델에 비해서 떨어진다.
Overlapped(Ⅰ), Overlapped(Ⅱ), Comlpetion Port (IOCP)
- 비동기 입출력을 사용하므로 성능이 높다.
■ 소켓 입출력 모델이 요구되는 사항
1. 소켓 함수 호출 시 블로킹을 최소화한다.
여섯가지 모델 모두 만족한다.
2. 입출력 작업을 다른 작업과 병행한다.
비동기 입출력 방식을 사용하는 Overlapped 모델(Ⅰ), Overlapped 모델(Ⅱ), Comlpetion Port 모델만 만족한다.
3. 스레드 개수를 최소화한다.
여섯가지 모델 모두 어느정도 만족한다.
64개 이상의 소켓을 만들시에는 WSAAsyncSelect 모델, Overlapped 모델(Ⅱ), Comlpetion Port 모델을 제외하고는
스레드를 추가로 생성한다.
하지만 WSAAsyncSelect 모델은 스레드 개수가 늘어나면 성능이 상당히 떨어져서 Overlapped 모델(Ⅱ), Comlpetion Port 모델만
이 조건을 만족한다. ( IOCP는 CPU 개수에 비례하여 작업자 스레드를 생성할 수 있으므로 가장 이상적이다. )
4. 유저모드와 커널모드 전환 횟수와 데이터 복사를 최소화한다.
비동기 입출력 방식을 사용하는 모델만 이 조건을 만족한다.
비동기 입출력을 할대 송신버퍼나 수신버퍼가 가득차면, 윈도우 운영체제는 애플리케이션 버퍼를 잠근후(lock),
이 메모리 영역을 직접 접근한다.
따라서 유저영역 ↔ 커널 영역 복사가 불필요하며 모드 전환없이 입출력 작업을 곧바로 이루므로 효율적이다.
※ 결론은 위의 모든 조건을 만족하는 모델은 Overlapped 모델(Ⅱ)과 IOCP 모델뿐이다.
하지만 성능 면에서 IOCP가 좋기 때문에 거의 모든 Server는 IOCP로 만든다.( 그 이외의 것을 사용한다는 소리는 들은 적이 없다. )
유저모드와 커널모드
■ 유저모드와 커널모드
Windows OS를 기준으로 설명드리자면, 프로세스(프로그램)를 실행하게 되면 유저모드와 커널모드를 오가면서 실행될 수 있습니다.
유저모드 : 유저가 접근할 수 있는 OS영역내에서 동작되는 실행모드입니다.
커널모드 : 유저모드로는 접근 할 수 없도록 되어있는 시스템영역(커널)에 접근하기 위해 동작되는 실행모드입니다.
이렇게 모드가 나뉜 이유는 보안성과 안전성의 확보 때문입니다. 만약에 유저(프로그래머)가 수시로 시스템영역을 맘대로 휘젓고 다닐 수있다면 가령, 메모리 할당하다가 운영체제가 사용하는 영역을 침범하는 등의 일이 가능하다면 곤란하겠죠.
그래서 민감한 영역내에 접근할 때를 제외하고 유저들이 마음대로 접근해도 되는 영역에 대해서 유저모드로 접근이 되도록 하고 커널에 요청해서 처리할 문제가 있을때만 일시적으로 커널모드로 전환해서 커널내의 처리요청을 처리하고 일을 마치면 다시 유저모드로 전환되서 실행이 되도록 하는 겁니다.
예를들어 쓰레드, 파일, 세마포어, 같은 커널오브젝트를 다룰때 CreateXXX()계열 함수를 호출하면 이 호출되는 시점은 유저모드에서 실행되지만 이 함수가 실행되면 커널모드로 전환되서 커널에게 오브젝트 생성을 요청을 하는겁니다.
( 함수이름으로 봐선 유저가 직접 만드는 듯한 착각을 일으켜줍니다만 아니더군요ㅎㅎ )
그리고 커널에서 만들어지든 실패하든 결과가 나와서 함수가 리턴되면 바로 자동으로 유저모드로 돌아오게 됩니다.
※ 유저모드와 커널모드의 전환은 속도면에서 상당한 시간을 처리합니다.
■ CPU 싸이클
CPU 싸이클은...Cycle은 CPU가 한번 연산하는데 걸리는 연산단위입니다
여기서는 "싸이클 = 연산" 정도로 보시면 될것같네요. 즉, 유저모드에서 커널모드로 전환하는데 CPU연산이 들어간다 라는 의미로 보시면 되고요. 상당히??? 인지는 잘 모르겠지만 CPU소모가 일어나는 건 맞습니다.
예를들어 동기화 객체를 쓸때 4가지 크리티컬섹션, 세마포어, 뮤텍스, 이벤트 를 쓰는데 크리티컬 섹션이 유저모드 동기화고, 나머지 3가지가 커널모드 동기화를 합니다. 즉 크리티컬 섹션으로 동기화 할 때의 장점이 유저모드로만 동작되기 때문에 유저모드->커널모드->유저모드로의 전환으로 소모되는 CPU싸이클이 다른 3가지 동기화모드와 달리 없어 가볍고 빠르게 사용할 수 있다는 것입니다
블로킹 소켓 VS 넌블로킹 소켓
■ 소켓모드
소켓은 소켓 함수 호출시 동작 방식에 따라 블로킹과 넌블로킹 소켓으로 구분하며 이를 소켓모드라고 부른다.
○ 블로킹 소켓
소켓 함수 호출 시 조건이 만족되지 않으면 함수는 리턴하지 않고 해당 스레드는 대기 상태가 된다.
소켓 함수는 리턴하지 않으므로 멀티스레드를 사용하여 다른 작업을 하지 않는 한 애플리케이션이 더는 진행할 수 없다.
socket() 함수는 기본적으로 블로킹 소켓이다.
○ 넌블로킹 소켓
소켓 함수 호출 시 조건이 만족되지 않더라도 함수가 리턴하므로 해당 스레드는 계속 진행 할 수 있다.
ioctlsocket()함수를 호출해야만 넌블로킹 소켓으로 바꿀 수 있다.
SOCKET listen_sock = socket( AF_INET, SOCK_STREAM, 0 );
u_long on = TRUE;
retval = ioctlsocket( listen_sock, FIONBIO, &on );
넌블로킹 소켓은 WSAGetLastError()함수를 호출하여 반드시 오류코드를 확인해야 한다.
WSAEWOULDBLOCK() -> 넌블로킹 소켓을 사용할 경우의 오류 코드.
이는 만족하지 않고 넘어간 것이므로 나중에 다시 소켓 함수를 호출하면 된다.
client_sock = accept( listen_sock, ( SOCKADDR* )&clientaddr, &addrlen );
if( client_sock == INVALID_SOCKET )
{
if( WSAGetLastError() != WSAEWOULDBLOCK )
{
// 에러 처리
}
continue;
}
넌블로킹 소켓에서는 다음과 같이 WSAEWOULDBLOCK를 항시 체크하여 다시 소켓함수를 호출하여야 한다.
※ listen_sock가 넌블로킹이면 client_sock도 넌블로킹 소켓이 된다.
■ 넌블로킹 소켓의 특징
장점 : 소켓 함수 호출 시 블록되지 않으므로 다른 작업을 진행 할 수 있다.
멀티스레드를 사용하지 않고 여러 개의 입출력을 처리 할 수 있다.
단점 : 소켓 함수를 호출할 때마다 WSAEWOULDBLOCK등 오류 코드를 확인하고,
다시 해당 함수를 호출해야하므로 프로그램 구조가 복잡해진다.
블로킹 소켓을 사용한 경우보다 CPU사용률이 높다.
■ 이상적인 소켓 입출력 모델
1. 모든 Client가 접속이 성공한다.
2. Server는 각 Client의 서비스 요청에 최대한 빠르게 반응하며 고속으로 데이터를 전송한다.
3. 위와 같은 기능을 제공하되 시스템 자원 사용량을 최소화한다. 즉 CPU 사용률이나 메모리 사용량등을 최소화한다.
■ 소켓 입출력 모델에 요구되는 사항
1. 소켓 함수 호출 시 블로킹을 최소화 한다.
CPU사용률을 최소한으로 하면서 넌블로킹 소켓을 사용한 모든 소켓 함수 호출을 성공시켜야 한다.
2. 입출력 작업을 다른 작업과 병행한다.
3. Thread 개수를 최소화한다.
Thread를 생성할 때마다 1MB의 메모리가 할당된다.
시스템 내의 Thread 수가 많아질수록 각 Thread의 응답속도는 느려지므로 결과적으로 Server의 성능 저하를 불러온다.
-> Context switching이 자주 발생하므로 늦어진다.
4. 유저모드와 커널모드 전환 횟수와 데이터 복사를 최소화 한다.
유저모드와 커널모드의 전환은 상당한 CPU 사이클을 소모한다.
소켓은 소켓 함수 호출시 동작 방식에 따라 블로킹과 넌블로킹 소켓으로 구분하며 이를 소켓모드라고 부른다.
○ 블로킹 소켓
소켓 함수 호출 시 조건이 만족되지 않으면 함수는 리턴하지 않고 해당 스레드는 대기 상태가 된다.
소켓 함수는 리턴하지 않으므로 멀티스레드를 사용하여 다른 작업을 하지 않는 한 애플리케이션이 더는 진행할 수 없다.
socket() 함수는 기본적으로 블로킹 소켓이다.
○ 넌블로킹 소켓
소켓 함수 호출 시 조건이 만족되지 않더라도 함수가 리턴하므로 해당 스레드는 계속 진행 할 수 있다.
ioctlsocket()함수를 호출해야만 넌블로킹 소켓으로 바꿀 수 있다.
SOCKET listen_sock = socket( AF_INET, SOCK_STREAM, 0 );
u_long on = TRUE;
retval = ioctlsocket( listen_sock, FIONBIO, &on );
넌블로킹 소켓은 WSAGetLastError()함수를 호출하여 반드시 오류코드를 확인해야 한다.
WSAEWOULDBLOCK() -> 넌블로킹 소켓을 사용할 경우의 오류 코드.
이는 만족하지 않고 넘어간 것이므로 나중에 다시 소켓 함수를 호출하면 된다.
client_sock = accept( listen_sock, ( SOCKADDR* )&clientaddr, &addrlen );
if( client_sock == INVALID_SOCKET )
{
if( WSAGetLastError() != WSAEWOULDBLOCK )
{
// 에러 처리
}
continue;
}
넌블로킹 소켓에서는 다음과 같이 WSAEWOULDBLOCK를 항시 체크하여 다시 소켓함수를 호출하여야 한다.
※ listen_sock가 넌블로킹이면 client_sock도 넌블로킹 소켓이 된다.
■ 넌블로킹 소켓의 특징
장점 : 소켓 함수 호출 시 블록되지 않으므로 다른 작업을 진행 할 수 있다.
멀티스레드를 사용하지 않고 여러 개의 입출력을 처리 할 수 있다.
단점 : 소켓 함수를 호출할 때마다 WSAEWOULDBLOCK등 오류 코드를 확인하고,
다시 해당 함수를 호출해야하므로 프로그램 구조가 복잡해진다.
블로킹 소켓을 사용한 경우보다 CPU사용률이 높다.
■ 이상적인 소켓 입출력 모델
1. 모든 Client가 접속이 성공한다.
2. Server는 각 Client의 서비스 요청에 최대한 빠르게 반응하며 고속으로 데이터를 전송한다.
3. 위와 같은 기능을 제공하되 시스템 자원 사용량을 최소화한다. 즉 CPU 사용률이나 메모리 사용량등을 최소화한다.
■ 소켓 입출력 모델에 요구되는 사항
1. 소켓 함수 호출 시 블로킹을 최소화 한다.
CPU사용률을 최소한으로 하면서 넌블로킹 소켓을 사용한 모든 소켓 함수 호출을 성공시켜야 한다.
2. 입출력 작업을 다른 작업과 병행한다.
3. Thread 개수를 최소화한다.
Thread를 생성할 때마다 1MB의 메모리가 할당된다.
시스템 내의 Thread 수가 많아질수록 각 Thread의 응답속도는 느려지므로 결과적으로 Server의 성능 저하를 불러온다.
-> Context switching이 자주 발생하므로 늦어진다.
4. 유저모드와 커널모드 전환 횟수와 데이터 복사를 최소화 한다.
유저모드와 커널모드의 전환은 상당한 CPU 사이클을 소모한다.
Thread / Context Switching
■ Thread
- 오늘날 우리가 사용하는 컴퓨터는 동시에 단 한 개의 명령어만을 처리할 수 있다. 하지만, 이 부분의 처리 속도는
매우 빠르기 때문에 순간 적으로 여러 개의 명령어를 처리하는 것처럼 보이게 되는데, 우리가 개발한 프로그램 역시
매우 빠른 속도로 처리된다. 때문에 두 가지 이상의 작업이 거의 동시에 발생되고 처리 되어지게 할 수 있다.
이렇게 작업을 병렬로 처리하는 것은 그 만큼 작업 시간이 줄어드는 것이므로 효율은 높아지게 된다.
우리가 구성할 네트워크는 매우 많은 패킷들을 순간적으로 처리해주어야 한다. 때문에 병렬 처리가 필수적이라 할 수
있는데, 쓰레드라는 개념을 사용하여 이 것을 구현할 수 있다.
■ Thread란?
- 하나의 작업 프로세스를 진행시키는 단위라고 이해하면 된다. 우리가 프로그램 하나를 만들 때 그 프로그램은 main을
갖고 있으며, 프로그램dms main에서부터 시작한다. 이 때 O/S는 실행될 프로그램에 쓰레드를 하나 할당하고, 그 쓰레드
는 main함수를 실행하게 된다. 이렇게 실행된 프로그램에는 시스템으로부터 기본적으로 하나의 쓰레드가 주어지는데,
이 것을 메인 쓰레드(Main thread)라고 한다.
2. Server에 다중 Thread를 적용한 경우 Accept Thread와 Worker Thread를 따로 두어서 Server의 일을 각각 분담하여 처리하고 있다. 각각의 Thread는 서로 다른 임무를 전문적으로 수행하고 있으므로, 처리속도도 빠를뿐아니라 효율도 올라갔다. 단, 너무 많은 Thread의 생성은 오히려 Server의 속도에 영향을 준다. 뱃사공이 많으면 배가 산으로 간다는 말과 비슷하다고 보면 된다.
- 쓰레드는 O/S에서의 기본적인 스케줄링 단위이다. 그리고 이러한 쓰레드를 O/S는 여러 개를 관리하면서 우리에게
이처럼 한 쓰레드에서 다른 쓰레드로 작업을 넘기는 과정을 Context Switching이라고 한다.
- 오늘날 우리가 사용하는 컴퓨터는 동시에 단 한 개의 명령어만을 처리할 수 있다. 하지만, 이 부분의 처리 속도는
매우 빠르기 때문에 순간 적으로 여러 개의 명령어를 처리하는 것처럼 보이게 되는데, 우리가 개발한 프로그램 역시
매우 빠른 속도로 처리된다. 때문에 두 가지 이상의 작업이 거의 동시에 발생되고 처리 되어지게 할 수 있다.
이렇게 작업을 병렬로 처리하는 것은 그 만큼 작업 시간이 줄어드는 것이므로 효율은 높아지게 된다.
우리가 구성할 네트워크는 매우 많은 패킷들을 순간적으로 처리해주어야 한다. 때문에 병렬 처리가 필수적이라 할 수
있는데, 쓰레드라는 개념을 사용하여 이 것을 구현할 수 있다.
■ Thread란?
- 하나의 작업 프로세스를 진행시키는 단위라고 이해하면 된다. 우리가 프로그램 하나를 만들 때 그 프로그램은 main을
갖고 있으며, 프로그램dms main에서부터 시작한다. 이 때 O/S는 실행될 프로그램에 쓰레드를 하나 할당하고, 그 쓰레드
는 main함수를 실행하게 된다. 이렇게 실행된 프로그램에는 시스템으로부터 기본적으로 하나의 쓰레드가 주어지는데,
이 것을 메인 쓰레드(Main thread)라고 한다.
Ctrl + Alt + Del을 눌린후 보기에서 Thread보기를 선택하면 위와 같이 나온다.
위에서 각 프로세스마다 Thread의 수가 다름을 알 수 있다. 최소 1개이상이 사용된다.
■ Thread의 효율성
- 우리가 만드는 응용프로그램은 기본적으로 하나의 쓰레드를 할당 받아 작업을 진행한다. 때문에, 우리가 사용하는
Windows O/S는 이미 여러 개의 쓰레드가 동작하고 있는 것이다. 1 개의 CPU에서는 동시에 1개의 연산만이 가능하다고
하였다. 하지만 그 처리속도는 매우 빠르기 때문에, 여러 개의 쓰레드를 순차적으로 처리하게 되면 거의 동시에 처리되
어 지는 것으로 보여지게 되며, 이러한 방법으로 O/S는 우리에게 멀티 테스킹(Multitasking)을 지원할 수 있는 것이다.
하나의 쓰레드가 시작되었다고 해서 그 쓰레드가 끝날 때 까지 연속된 작업을 진행하는 것이 아니다. O/S는 쓰레드
하나가 한번에 진행할 수 있는 단위를 정하고 각 쓰레드들의 작업을 조금씩 진행시키는 병렬 처리를 한다.
이렇게 병렬로 작업되는 쓰레드를 우리는 응용 프로그램에서 임의로 생성하고 작업을 할당할 수 있다. 즉, 우리의
프로그램이 내부에서 작업을 병렬로 처리할 수 있다는 의미이다.
예를 들어, 한 서버에 두개의 클라이언트가 접속하였다고 하자. 클라이언트 들은 서로 작업 요청을 서버에 하게 되는데,
만일 서버가 메인 쓰레드만으로 모든 작업을 처리하려 한다면, 클라이언트로부터 들어오는 패킷을 쌓아놓고 순차적으
로 읽어 들여 처리하고 다시 통보해주어야 한다.
만일 여기에서 쓰레드를 더 생성하여 네트워크 작업과 내부 연산 작업을 병렬로 처리한다면 그만큼 처리 속도를 높일 수
있을 것이다.
1. Server에 단일 Thread를 적용한 경우
Main Thread에서 모든 일들을 다 수행하고 있어서 순차적으로 읽어서 처리하고 다시 통보하므로, 속도가 느리고 비효율적이다.
■ Context Switching
- 쓰레드는 O/S에서의 기본적인 스케줄링 단위이다. 그리고 이러한 쓰레드를 O/S는 여러 개를 관리하면서 우리에게
멀티 태스킹을 가능하게 해준다. 하지만 앞서 일반적인 CPU는 한번에 한가지 명령만을 계산할 수 있다고 하였다.
단지 여러 쓰레드의 순차적인 관리를 통해 거의 동시에 진행하게끔 한다고 하였는데, 이러한 관리를 위해서 쓰레드를
O/S에서 관리할 수 있는 기본적인 정보가 있어야 한다.
쓰레드는 레지스터(Register Set), 커널 스택(Kernel Stack), 사용자 스택 등의 여러 정보를 갖고 있는데, 이러한 정보들을
Context라고 한다. Context들은 쓰레드가 작업을 진행하는 동안 작업에 대한 정보를 보관하고 있으며, 다른 쓰레드로
작업 순서가 넘어갈 때 저장된다.
O/S는 쓰레드 하나의 작업을 진행하기 위해 그 쓰레드의 Context를 읽어오며, 다시 다른 쓰레드로 작업을 변경할 때
이전 쓰레드의 Context를 저장하고 다시 진행할 쓰레드의 Context를 읽어오는 작업을 반복하게된다.
이처럼 한 쓰레드에서 다른 쓰레드로 작업을 넘기는 과정을 Context Switching이라고 한다.
우리의 응용 프로그램 차원에서 보면, Context Switching이라는 작업은 아주 미묘하고 작은 단위이다. 그 속도 또한
무시해도 될 만큼 빠르기 때문에 우리는 그다지 신경을 쓰지 않아도 프로그램은 아주 잘 동작할 것이다.
하지만, 이렇게 처리해야 할 쓰레드의 개수가 매우 많다면 어떻게 될까? Windows O/S를 사용할 때 많은 프로그램들을
띄워놓고 작업하면 속도가 상당히 떨어짐을 느낄 수 있는데, 이 것은 작업해야 할 쓰레드가 많아짐에 따라 Context
Switching이 매우 빈번하게 발생하며, 다시 차례가 돌아오기까지의 시간이 더 소비되기 때문이다.
이처럼 Context Switching 작업은 매우 미묘할지라도 멀티 쓰레딩을 해야 하는 상황에서는 쓰레드의 개수에 신경을
써 주어야 한다. 병렬처리로 인해 작업 속도를 증가시킬 수는 있겠지만, 개수가 너무 많아지게 된다면 오히려 역효과를
가져올 수도 있으므로 신경써서 작업하고 성능 테스트를 꼭 해보길 바란다.
테스트라함은 작업관리자를 띄워서 성능을 봤을때 CPU의 사용률을 보면 알 수가 있다. Server를 만들어서 CPU사용률을
체크하는 습관을 가지자..
Ex)
while( 1 )
{
if( count == 0 ) // Sleep(1)을 걸어주지 않으면 CPU의 사용률은 100%이다.
Sleep( 1 );
Sleep( 1 );
}
- 위의 코드는 WorkerThread의 일부분을 단적인 예로 보여진 부분이다. 여기서 접속한 User가 아무도 없을 경우 미친듯이
while문을 돌게 된다.
그러면 CPU의 사용률이 100%을 보이지만, User가 아무도 없을시에 Sleep(1)을 걸어주면, CPU의 사용률이 10%이하로
내려감을 볼 수가 있다.
멀티 프로세스와 멀티 쓰레드
■ 멀티 프로세스와 멀티 쓰레드
이 두가지는 동시에 두 가지 이상의 루틴을 실행 할 수 있는 역활을 한다.
( 실제로 동시에 여러가지가 아니고 cpu가 하나라면 한 클럭에 하나의 명령만 실행할수 있다.
cpu가 두개라면 두번.. 보통 cpu가 많아봤자 네개 이다. 어쨌건 OS에서는 재주껏 분산해서 멀티로 돌아가는 것처럼 보이게 한다. )
멀티 프로세스는 일단 포크라는것을 한다. 그래서 윈도우 작업관리자에서 관리되는 프로세스가 하나가 더는다.
유닉스 계열에서는 ps 명령어로 보면 알수 있다. 포크를 하면 하나의 프로세스가 두개의 프로세스로 늘어난다.
이 프로세스들은 서로 통신을 할려면 IPC( 세마포어, 큐, 공유메모리 )를 통해야만 한다.
왜냐면 전혀 다른 프로세스니까.. ( 물론 포크되었으므로 부모 자식의 관계는 있다. )
즉 똑같은 프로그램이 복사가 되서 새로 뜨는것이다. ( 물론 이놈이 포크되기 전인지 후인지 알수 있다. )
멀티 쓰레드는 프로세스를 복사하는것이 아니라 Function 단위로 실행시키는 것이다.
즉 어떤 Function에서 다른 Function을 호출하면서 그 밑의 루틴을 다시 실행하는 것이다.
이 것은 같은 프로세스이므로 멀티 프로세스에 비해서 부하를 덜준다. ( 그래서 경량프로세스란 말을 하는 것이다. )
또한 다른 장점이 부 쓰레드내에 특정변수 메모리번지를 알아 낼 수 있다면 그 메모리에 접근이 가능하다.
왜냐면 같은 프로세스니까 운영체제를 통해서 접근가능하게 지원이 되는것이다.
결론은 멀티 프로세스는 똑같은 놈이 하나 더 늘어나는거고, 멀티 쓰레드는 함수가 백그라운드에서 따로 실행이 되는것이다.
■ 멀티 프로세스와 멀티 쓰레드의 동작원리
일반적인 개념에서 멀티 쓰레드가 멀티 프로세스 보다 효율적이다. 왜 그런지 살펴보면..
프로그램이 동작하기 위해서는 두가지의 메모리 공간이 필요하게 되는데 그것이 바로 코드공간과 데이터 공간이다.
코드 공간 : 특정 프로세스의 동작상태를 기록하는 것으로 하나의 프로세스가 독립적인 코드 포인터를 가지고 동작하기 위해 필요하다.
데이터 공간 : 하나의 프로세스가 작동 중에 필요로 하는 데이터를 저장해 두기 위한 것으로 프로그램 변수나 메모리 스택 공간을 말한다.
하나의 프로세스는 동작하기 위해 이러한 두가지의 공간을 모두 요구하게 되는데.. 멀티 프로세스란 이러한 개별적인 프로세스들이 서로 간에 독립적인 코드공간과 데이터 공간을 유지하면서 함께 작동할 수 있는 상태를 말한다.
반면에 쓰레드란 좀더 작은 규모의 프로세스를 말한다. 다수 개의 쓰레드는 하나의 프로세스 하부에서 나타나는데 이들은 독립적인 코드
공간을 가지고 개별적으로 작동할 수 있지만, 독립적인 데이터 공간을 가지지 않으므로 하나의 프로세스 아래에 있는 모든 쓰레드들은 해당 프로세스의 데이터 공간을 각각 공유하게 된다.
멀티쓰레드란 이런 방식으로 하나의 프로세스가 다수 개의 작업을 각각 스레드를 이용하여 동시에 작동 시킬 수 있는 것을 말하는데 보통 쓰레드의 생성과 파괴는 코드공간의 관리 만을 필요로 하기 때문에 프로세스의 생성과 파괴보다 훨씬 적은 자원을 소모한다. 이 때문에 멀티 쓰레드는 동일 작업을 위한 멀티 프로세스보다 훨씬 효율적이라고 이야기한다.
■ 멀티쓰레드의 효율성과 안정성 문제
다수개의 쓰레드가 동일한 데이터 공간을 공유하면서 이들을 수정한다는 점에 필연적으로 생기는 문제이다.
멀티 프로세스의 방식의 프로그램에서 하나의 프로세스가 자신의 데이터 공간을 망가뜨린다면 그것은 해당 프로세스의 중단을 낳게 될 것이다. 하지만 멀티 쓰레드 방식의 프로그램에서는 하나의 쓰레드가 자신이 사용하던 데이터 공간을 망가뜨린다면 그 결과는 하나의 데이터 공간을 공유하는 모든 쓰레드를 작동불능 상태로 만들어 버릴 것 이다. 이러한 문제에 대비하기 위해 Critical Section 기법이 존재한다.
이 두가지는 동시에 두 가지 이상의 루틴을 실행 할 수 있는 역활을 한다.
( 실제로 동시에 여러가지가 아니고 cpu가 하나라면 한 클럭에 하나의 명령만 실행할수 있다.
cpu가 두개라면 두번.. 보통 cpu가 많아봤자 네개 이다. 어쨌건 OS에서는 재주껏 분산해서 멀티로 돌아가는 것처럼 보이게 한다. )
멀티 프로세스는 일단 포크라는것을 한다. 그래서 윈도우 작업관리자에서 관리되는 프로세스가 하나가 더는다.
유닉스 계열에서는 ps 명령어로 보면 알수 있다. 포크를 하면 하나의 프로세스가 두개의 프로세스로 늘어난다.
이 프로세스들은 서로 통신을 할려면 IPC( 세마포어, 큐, 공유메모리 )를 통해야만 한다.
왜냐면 전혀 다른 프로세스니까.. ( 물론 포크되었으므로 부모 자식의 관계는 있다. )
즉 똑같은 프로그램이 복사가 되서 새로 뜨는것이다. ( 물론 이놈이 포크되기 전인지 후인지 알수 있다. )
멀티 쓰레드는 프로세스를 복사하는것이 아니라 Function 단위로 실행시키는 것이다.
즉 어떤 Function에서 다른 Function을 호출하면서 그 밑의 루틴을 다시 실행하는 것이다.
이 것은 같은 프로세스이므로 멀티 프로세스에 비해서 부하를 덜준다. ( 그래서 경량프로세스란 말을 하는 것이다. )
또한 다른 장점이 부 쓰레드내에 특정변수 메모리번지를 알아 낼 수 있다면 그 메모리에 접근이 가능하다.
왜냐면 같은 프로세스니까 운영체제를 통해서 접근가능하게 지원이 되는것이다.
결론은 멀티 프로세스는 똑같은 놈이 하나 더 늘어나는거고, 멀티 쓰레드는 함수가 백그라운드에서 따로 실행이 되는것이다.
■ 멀티 프로세스와 멀티 쓰레드의 동작원리
일반적인 개념에서 멀티 쓰레드가 멀티 프로세스 보다 효율적이다. 왜 그런지 살펴보면..
프로그램이 동작하기 위해서는 두가지의 메모리 공간이 필요하게 되는데 그것이 바로 코드공간과 데이터 공간이다.
코드 공간 : 특정 프로세스의 동작상태를 기록하는 것으로 하나의 프로세스가 독립적인 코드 포인터를 가지고 동작하기 위해 필요하다.
데이터 공간 : 하나의 프로세스가 작동 중에 필요로 하는 데이터를 저장해 두기 위한 것으로 프로그램 변수나 메모리 스택 공간을 말한다.
하나의 프로세스는 동작하기 위해 이러한 두가지의 공간을 모두 요구하게 되는데.. 멀티 프로세스란 이러한 개별적인 프로세스들이 서로 간에 독립적인 코드공간과 데이터 공간을 유지하면서 함께 작동할 수 있는 상태를 말한다.
반면에 쓰레드란 좀더 작은 규모의 프로세스를 말한다. 다수 개의 쓰레드는 하나의 프로세스 하부에서 나타나는데 이들은 독립적인 코드
공간을 가지고 개별적으로 작동할 수 있지만, 독립적인 데이터 공간을 가지지 않으므로 하나의 프로세스 아래에 있는 모든 쓰레드들은 해당 프로세스의 데이터 공간을 각각 공유하게 된다.
멀티쓰레드란 이런 방식으로 하나의 프로세스가 다수 개의 작업을 각각 스레드를 이용하여 동시에 작동 시킬 수 있는 것을 말하는데 보통 쓰레드의 생성과 파괴는 코드공간의 관리 만을 필요로 하기 때문에 프로세스의 생성과 파괴보다 훨씬 적은 자원을 소모한다. 이 때문에 멀티 쓰레드는 동일 작업을 위한 멀티 프로세스보다 훨씬 효율적이라고 이야기한다.
■ 멀티쓰레드의 효율성과 안정성 문제
다수개의 쓰레드가 동일한 데이터 공간을 공유하면서 이들을 수정한다는 점에 필연적으로 생기는 문제이다.
멀티 프로세스의 방식의 프로그램에서 하나의 프로세스가 자신의 데이터 공간을 망가뜨린다면 그것은 해당 프로세스의 중단을 낳게 될 것이다. 하지만 멀티 쓰레드 방식의 프로그램에서는 하나의 쓰레드가 자신이 사용하던 데이터 공간을 망가뜨린다면 그 결과는 하나의 데이터 공간을 공유하는 모든 쓰레드를 작동불능 상태로 만들어 버릴 것 이다. 이러한 문제에 대비하기 위해 Critical Section 기법이 존재한다.
How do I decide whether to use ATL, MFC, Win32 or CLR for a new C++ project?
http://stackoverflow.com/questions/821676/how-do-i-decide-whether-to-use-atl-mfc-win32-or-clr-for-a-new-c-project
It depends on your needs.
Using the CLR will provide you with the most expressive set of libraries (the entire .NET framework), at the cost of restricting your executable to requiring the .NET framework to be installed at runtime, as well as limiting you to the Windows platform (however, all 4 listed technologies are windows only, so the platform limitation is probably the least troublesome).
However, CLR requires you to use the C++/CLI extensions to the C++ language, so you'll, in essense, need to learn some extra language features in order to use this. Doing so gives you many "extras," such as access to the .net libraries, full garbage collection, etc.
ATL & MFC are somewhat trickier to decide between. I'd refer you to MSDN's page for choosing in order to decide between them. The nice thing about ATL/MFC is that you don't need the .NET framework, only the VC/MFC runtimes to be installed for deployment.
Using Win32 directly provides the smallest executables, with the fewest dependencies, but is more work to write. You have the least amount of helper libraries, so you're writing more of the code.
It depends on your needs.
Using the CLR will provide you with the most expressive set of libraries (the entire .NET framework), at the cost of restricting your executable to requiring the .NET framework to be installed at runtime, as well as limiting you to the Windows platform (however, all 4 listed technologies are windows only, so the platform limitation is probably the least troublesome).
However, CLR requires you to use the C++/CLI extensions to the C++ language, so you'll, in essense, need to learn some extra language features in order to use this. Doing so gives you many "extras," such as access to the .net libraries, full garbage collection, etc.
ATL & MFC are somewhat trickier to decide between. I'd refer you to MSDN's page for choosing in order to decide between them. The nice thing about ATL/MFC is that you don't need the .NET framework, only the VC/MFC runtimes to be installed for deployment.
Using Win32 directly provides the smallest executables, with the fewest dependencies, but is more work to write. You have the least amount of helper libraries, so you're writing more of the code.
The .NET Framework - What About Speed?
The .NET Framework - What About Speed?
Speed is important, of course. For an in-depth discussion of speed considerations in managed
code, I will refer you to a few excellent articles in the MSDN Library (msdn.Microsoft. com/library):
-“A Baker’s Dozen: Thirteen Things You Should Know Before Porting Your Visual C++ .NET Programs to Visual Studio 2005” by Stanley Lippman.
-“Best Practices for Writing Efficient and Reliable Code with C++/CLI” by Kenny Kerr.
-“C++: The Most Powerful Language for .NET Framework Programming” by Kenny Kerr.
-“Writing Faster Managed Code: Know What Things Cost” by Jan Gray.
-“Writing High-Performance Managed Applications: A Primer” by Gregor Noriskin (includes an overview of the CLR Profiler).
-“Tips for Improving Time-Critical Code”.
-“Optimization Best Practices” in the Visual C++ section.
Speed is important, of course. For an in-depth discussion of speed considerations in managed
code, I will refer you to a few excellent articles in the MSDN Library (msdn.Microsoft. com/library):
-“A Baker’s Dozen: Thirteen Things You Should Know Before Porting Your Visual C++ .NET Programs to Visual Studio 2005” by Stanley Lippman.
-“Best Practices for Writing Efficient and Reliable Code with C++/CLI” by Kenny Kerr.
-“C++: The Most Powerful Language for .NET Framework Programming” by Kenny Kerr.
-“Writing Faster Managed Code: Know What Things Cost” by Jan Gray.
-“Writing High-Performance Managed Applications: A Primer” by Gregor Noriskin (includes an overview of the CLR Profiler).
-“Tips for Improving Time-Critical Code”.
-“Optimization Best Practices” in the Visual C++ section.
Tips for Improving Time-Critical Code
http://msdn.microsoft.com/en-us/library/eye126ky.aspx
http://kyuniitale.blog.me/40028835071
http://kyuniitale.blog.me/40028835071
Writing fast code requires understanding all aspects of your application and how it interacts with the system. This topic suggests alternatives to some of the more obvious coding techniques to help you ensure that the time-critical portions of your code perform satisfactorily.
To summarize, improving time-critical code requires that you:
To summarize, improving time-critical code requires that you:
- Know which parts of your program have to be fast.
- Know the size and speed of your code.
- Know the cost of new features.
- Know the minimum work needed to accomplish the job.

Missed cache hits, on both the internal and external cache, as well as page faults (going to secondary storage for program instructions and data) slow the performance of a program.
A CPU cache hit can cost your program 10–20 clock cycles. An external cache hit can cost 20–40 clock cycles. A page fault can cost one million clock cycles (assuming a processor that handles 500 million instructions/second and a time of 2 millisecond for a page fault). Therefore, it is in the best interest of program execution to write code that will reduce the number of missed cache hits and page faults.
One reason for slow programs is that they take more page faults or miss the cache more often than necessary. To avoid this, it's important to use data structures with good locality of reference, which means keeping related things together. Sometimes a data structure that looks great turns out to be horrible because of poor locality of reference, and sometimes the reverse is true. Here are two examples:
- Dynamically allocated linked lists can reduce program performance because when you search for an item or when you traverse a list to the end, each skipped link could miss the cache or cause a page fault. A list implementation based on simple arrays might actually be much faster because of better caching and fewer page faults even — allowing for the fact that the array would be harder to grow, it still might be faster.
- Hash tables that use dynamically allocated linked lists can degrade performance. By extension, hash tables that use dynamically allocated linked lists to store their contents might perform substantially worse. In fact, in the final analysis, a simple linear search through an array might actually be faster (depending on the circumstances). Array-based hash tables (so-called "closed hashing") is an often-overlooked implementation which frequently has superior performance.
Sorting is inherently time consuming compared to many typical operations. The best way to avoid unnecessary slowdown is to avoid sorting at critical times. You may be able to:
- Defer sorting until a non-performance–critical time.
- Sort the data at an earlier, non-performance–critical time.
- Sort only the part of the data that truly needs sorting.
Sometimes, you can build the list in sorted order. Be careful, because if you need to insert data in sorted order, you may require a more complicated data structure with poor locality of reference, leading to cache misses and page faults. There is no approach that works in all cases. Try several approaches and measure the differences.
Here are some general tips for sorting:
- Use a stock sort to minimize bugs.
- Any work you can do beforehand to reduce the complexity of the sort is worthwhile. If a one-time pass over your data simplifies the comparisons and reduces the sort from O(n log n) to O(n), you will almost certainly come out ahead.
- Think about the locality of reference of the sort algorithm and the data you expect it to run on.
There are fewer alternatives for searches than for sorting. If the search is time-critical, a binary search or hash table lookup is almost always best, but as with sorting, you must keep locality in mind. A linear search through a small array can be faster than a binary search through a data structure with a lot of pointers that causes page faults or cache misses.
The Microsoft Foundation Classes (MFC) can greatly simplify writing code. When writing time-critical code, you should be aware of the overhead inherent in some of the classes. Examine the MFC code that your time-critical code uses to see if it meets your performance requirements. The following list identifies MFC classes and functions you should be aware of:
- CString MFC calls the C run-time library to allocate memory for a CString dynamically. Generally speaking, CString is as efficient as any other dynamically-allocated string. As with any dynamically allocated string, it has the overhead of dynamic allocation and release. Often, a simple char array on the stack can serve the same purpose and is faster. Don't use a CString to store a constant string. Use const char * instead. Any operation you perform with a CString object has some overhead. Using the run-time library string functions may be faster.
- CArray A CArray provides flexibility that a regular array doesn't, but your program may not need that. If you know the specific limits for the array, you can use a global fixed array instead. If you use CArray, use CArray::SetSize to establish its size and specify the number of elements by which it grows when a reallocation is necessary. Otherwise, adding elements can cause your array to be frequently reallocated and copied, which is inefficient and can fragment memory. Also be aware that if you insert an item into an array, CArray moves subsequent items in memory and may need to grow the array. These actions can cause cache misses and page faults. If you look through the code that MFC uses, you may see that you can write something more specific to your scenario to improve performance. Since CArray is a template, for example, you might provide CArray specializations for specific types.
- CList CList is a doubly linked list, so element insertion is fast at the head, tail, and at a known position (POSITION) in the list. Looking up an element by value or index requires a sequential search, however, which can be slow if the list is long. If your code does not require a doubly linked list you may want to reconsider using CList. Using a singly linked list saves the overhead of updating an additional pointer for all operations as well as the memory for that pointer. The additional memory is not great, but it is another opportunity for cache misses or page faults.
- IsKindOf This function can generate many calls and access a lot of memory in different data areas, leading to bad locality of reference. It is useful for a debug build (in an ASSERT call, for example), but try to avoid using it in a release build.
- PreTranslateMessage Use PreTranslateMessage when a particular tree of windows needs different keyboard accelerators or when you must insert message handling into the message pump. PreTranslateMessage alters MFC dispatch messages. If you override PreTranslateMessage, do so only at the level needed. For example, it is not necessary to override CMainFrame::PreTranslateMessage if you are interested only in messages going to children of a particular view. Override PreTranslateMessage for the view class instead.
Do not circumvent the normal dispatch path by using PreTranslateMessage to handle any message sent to any window. Use window procedures and MFC message maps for that purpose. - OnIdle Idle events can occur at times you do not expect, such as between WM_KEYDOWN and WM_KEYUP events. Timers may be a more efficient way to trigger your code. Do not force OnIdle to be called repeatedly by generating false messages or by always returning TRUE from an override of OnIdle, which would never allow your thread to sleep. Again, a timer or a separate thread might be more appropriate.
Code reuse is desirable. However, if you are going to use someone else's code, you should make sure you know exactly what it does in those cases where performance is critical to you. The best way to understand this is by stepping through the source code or by measuring with tools such as PView or Performance Monitor.
Use multiple heaps with discretion. Additional heaps created with HeapCreate and HeapAlloc let you manage and then dispose of a related set of allocations. Don't commit too much memory. If you're using multiple heaps, pay special attention to the amount of memory that is initially committed.
Instead of multiple heaps, you can use helper functions to interface between your code and the default heap. Helper functions facilitate custom allocation strategies that can improve the performance of your application. For example, if you frequently perform small allocations, you may want to localize these allocations to one part of the default heap. You can allocate a large block of memory and then use a helper function to suballocate from that block. If you do this, you will not have additional heaps with unused memory because the allocation is coming out of the default heap.
In some cases, however, using the default heap can reduce locality of reference. Use Process Viewer, Spy++, or Performance Monitor to measure the effects of moving objects from heap to heap.
Measure your heaps so you can account for every allocation on the heap. Use the C run-time debug heap routines to checkpoint and dump your heap. You can read the output into a spreadsheet program like Microsoft Excel and use pivot tables to view the results. Note the total number, size, and distribution of allocations. Compare these with the size of working sets. Also look at the clustering of related-sized objects.
You can also use the performance counters to monitor memory usage.
For background tasks, effective idle handling of events may be faster than using threads. It's easier to understand locality of reference in a single-threaded program.
A good rule of thumb is to use a thread only if an operating system notification that you block on is at the root of the background work. Threads are the best solution in such a case because it is impractical to block a main thread on an event.
Threads also present communication problems. You must manage the communication link between your threads, with a list of messages or by allocating and using shared memory. Managing the communication link usually requires synchronization to avoid race conditions and deadlock problems. This complexity can easily turn into bugs and performance problems.
For additional information, see Idle Loop Processing and Multithreading.
Smaller working sets mean better locality of reference, fewer page faults, and more cache hits. The process working set is the closest metric the operating system directly provides for measuring locality of reference.
- To set the upper and lower limits of the working set, use SetProcessWorkingSetSize.
- To get the upper and lower limits of the working set, use GetProcessWorkingSetSize.
- To view the size of the working set, use Spy++.
피드 구독하기:
덧글 (Atom)